应用自然语言处理(NLP)来训练聊天机器人提供了数据漂移的另一个有用的例子。我们使用语言的方式正在不断演变,因此必须更新用于聊天机器人的训练数据的语义分析,来反映当前的语言。想象一下,尝试使用1980年代的培训数据来训练聊天机器人与现代消费者进行互动。在40年中,语言可能会发生重大变化,这迫使人们需要更新训练数据。
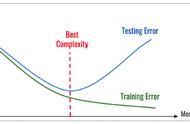
这一现象已经有了多种描述方法,包括数据漂移、概念漂移和模型衰减。不管你怎么称呼它,它都代表了机器学习的硬道理:在未来的某个时候,你的训练数据将不再为准确的预测提供基础。
如何应对这个不可避免的挑战呢?答案是定期使用新的或扩展的数据重新训练你的模型。实际上,训练你的模型是一个持续的过程,特别是在质量要求很高的情况下。
你应该如何更新你的机器学习模型?简单来说,你有两个选择:使用更新的输入手动重新训练模型,或构建一个旨在从新数据中不断学习的模型。

手动模型重新训练方法
手动更新机器学习模型的方法本质上是复制你的初始训练数据过程,但要使用一组更新的数据输入。在这种情况下,你可以决定如何以及何时向算法提供新数据。
此选项的可行性取决于你定期获取和准备新训练数据的能力。你可以随时监控模型的性能,确定何时需要更新。如果模型的准确性明显下降,则可能需要对更新的数据进行重新训练。
这种方法的优点之一是修修补补通常可以带来真知灼见和创新。如果密切监视模型并找出缺点,你可能会发现包含额外数据或以更基本的方式修改算法的价值。


模型训练的持续学习方法
持续学习模型通常会从部署了数据的生产环境中合并新的数据流。
消费者每天都会参与持续学习的机器学习模型。以音乐流媒体平台Spotify为例,该平台使用协作过滤功能,根据具有相似爱好的其他用户的偏好向用户提供推荐,来创造价值和竞争优势。
当Spotify用户收听音乐时,与他们的选择有关的数据会反馈到公司的预测算法中。由此产生的反馈循环完善了该应用为其用户提供的推荐,并允许高级个性化设置,例如机器生成的个性化播放列表。Netflix等其他领先的消费媒体服务提供商也使用类似的持续学习系统。
如你所料,构建这些系统所需的技术专业知识和资源对于许多组织来说根本无法满足。此外,你需要稳定的数据流来进行自动集成。在持续学习模型中,人为干预是可能的,但它代表了一个真正的瓶颈。例如,Spotify在将其数百万用户生成的数据反馈回其算法之前,不需要对其进行清理或格式化。
无论是手动更新还是持续学习似乎都是更有效(可行)的选择,你需要从战略上考虑用于生成新数据来进行再培训的劳动力和技术。如果你打算在可预见的将来使用你的模型,则需要合适的资源来保持该模型最新。