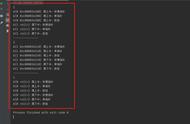
其代码如下:
//删除元素
intdelete_list(list*head){
if(head==NULL){
printf("链表为空!\n");
return0;
}
//建立临时结点存储头结点信息(目的为了找到退出点)
//如果不这么建立的化需要使用一个数据进行计数标记,计数达到链表长度时自动退出
//循环链表当找到最后一个元素的时候会自动指向头元素,这是我们不想让他发生的
list*temp=head;
list*ptr=head->next;
intdel;
printf("请输入你要删除的元素:");
scanf("%d",&del);
while(ptr!=head){
if(ptr->data==del){
if(ptr->next==head){
temp->next=head;
free(ptr);
return1;
}
temp->next=ptr->next;//核心删除操作代码
free(ptr);
//printf("元素删除成功!\n");
return1;
}
temp=temp->next;
ptr=ptr->next;
}
printf("没有找到要删除的元素\n");
return0;
}
循环单链表的遍历
与普通的单链表和双向链表的遍历不同,循环链表需要进行结点的特殊判断。
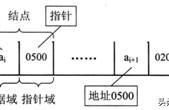
先找到尾节点的位置,由于尾节点的next指针是指向头结点的,所以不能使用链表本身是否为空(NULL)的方法进行简单的循环判断,我们需要通过判断结点的next指针是否等于头结点的方式进行是否完成循环的判断。
此外还有一种计数的方法,即建立一个计数器count=0,每一次next指针指向下一个结点时计数器 1,当count数字与链表的节点数相同的时候即完成循环;
但是这样做会有一个问题,就是获取到链表的节点数同时,也需要完成一次遍历才可以达成目标。
其代码如下:
//遍历元素
intdisplay(list*head){
if(head!=NULL){
list*p=head;
//遍历头节点到,最后一个数据
while(p->next!=head){
printf("%d",p->next->data);
p=p->next;
}
printf("\n");//换行
//把最后一个节点赋新的节点过去
return1;
}else{
printf("头结点为空!\n");
return0;
}
}
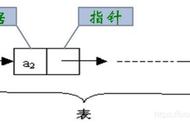
进阶概念——双向循环链表
循环单链表也有一个孪生兄弟——双向循环链表,其设计思路与单链表和双向链表的设计思路一样,就是在原有的双向链表的基础上,将尾部结点和头部结点进行互相连接。交给大家了。
关于链表的总结在顺序表中做插入删除操作时,平均移动大约表中一半的元素,因此对n较大的顺序表效率低。并且需要预先分配足够大的存储空间,而链表恰恰是其中运用的精华。
基于存储,运算,环境这几方面考虑,可以让我们更好的在项目中使用链表。
今天链表基础就讲到这里,下一期,我们再见!
,