由于上传限制只能分章节上传,并且图片和公式可能无法上传出现乱码影响阅读。需要完整资料的小伙伴可以评论区留言或者私聊。专业整理考研资料欢迎随时咨询
第1章 绪论
节:数据结构的基本概念(定义)
1.数据(Data)
定义
数据是描述客观事物的数值、字符以及能输入机器且能被处理的各种符号集合。
数据包含整型、实型、布尔型、图象、字符、声音等一切可以输入到计算机中的符号集合。
例如对C源程序
2.数据元素(DataElement)
定义
数据元素是组成数据的基本单位,是数据集合的个体,在计算机中通常作为一个整体进行考虑和处理。例如:
3.数据对象(DataObject)
定义
数据对象是性质相同的数据元素的集合,是数据的一个子集。
例如:整数集合:N={0,±1,±2,…}无限集
字符集合:C={ˊAˊ,Bˊ,…,ˊZˊ}有限集
4.数据结构(Data Structure)
(1)定义
数据结构是指相互之间存在一种或多种特定关系的数据元素集合,是带有结构的数据元素的集合,它指的是数据元素之间的相互关系,即数据的组织形式。例如表结构:
(2)树型结构
(3)图结构
5.数据类型(DataType)
定义
数据类型是一组性质相同的值集合以及定义在这个值集合上的一组操作的总称。
如在高级语言中,整型类型的取值范围为:
-32768~ 32767,运算符集合为加、减、乘、除、取模,即 、-、*、/、%
(1)高级语言中的数据类型分为两大类:
①原子类型,其值不可分解。如C语言中的标准类型(整型、实型、字符型、)。
②结构类型,其值是由若干成分按某种结构组成的,因此是可以分解的,并且它的成分可以是非结构的,也可以是结构的。
6.数据抽象与抽象数据类型
(1)数据的抽象
(2)抽象数据类型(AbstractDataType)
(3)抽象数据类型实现
(4)ADT的表示与实现
(5)面向对象的概念
(6)结构化的开发方法与面向对象开发方法不同点
【核心笔记】数据结构的内容
1.逻辑结构
(1)定义
数据的逻辑结构是指数据元素之间逻辑关系描述。
(2)形式化描述:Data_Structure=(D,R)其中D是数据元素的有限集,R是D上关系的有限集。
(3)四类基本的结构
集合结构、线性结构、树型结构、图状结构。
2.集合结构
(1)定义:结构中的数据元素之间除了同属于一个集合的关系外,无任何其它关系。
例如
集合
3.线性结构
定义:结构中的数据元素之间存在着一对一的线性关系。
例如:线性表
4.树型结构
定义:结构中的数据元素之间存在着一对多的层次关系。
例如:树
5.图状结构或网状结构
定义:结构中的数据元素之间存在着多对多的任意关系。
例如
6.逻辑结构
综上所述,数据的逻辑结构可概括为
逻辑结构
线性结构——线性表、栈、队、字符串数组、广义表
非线性结构——树、图
7.存储结构
(1)定义:存储结构(又称物理结构)是逻辑结构在计算机中存储映象,是逻辑结构在计算机中的实现,它包括数据元素的表示和关系的表示。
(2)形式化描述:
D要存入机器中,建立一从D的数据元素到存储空间M单元映象S,D→M,即对于每一个d,d∈D,都有唯一的z∈M使S(D)=Z,同时这个映象必须明显或隐含地体现关系R。
(3)逻辑结构与存储结构的关系为:
存储结构是逻辑关系的映象与元素本身映象,是数据结构的实现;逻辑结构是数据结构的抽象。
(4)数据元素之间关系在计算机中的表示方法:
顺序映象(顺序存储结构)
非顺序映象(非顺序存储结构)
8.运算集合
例如工资表
9.数据结构的内容
综上所述,数据结构的内容可归纳为三个部分
逻辑结构、存储结构和运算集合:按某种逻辑关系组织起来的一批数据,按一定的映象方式把它存放在计算机存贮器中,并在这些数据上定义了一个运算的集合,就叫做数据结构。
【核心笔记】算法
1.算法(Algorithm)定义
定义:算法是规则的有限集合,是为解决特定问题而规定的一系列操作。
2.算法的特性
(1)有限性:有限步骤之内正常结束,不能形成无穷循环
(2)确定性:算法中的每一个步骤必须有确定含义,无二义性得以实现。
(3)输入:有多个或0个输入
(4)输出:至少有一个或多个输出
(5)可行性:原则上能精确进行,操作可通过已实现基本运算执行有限次而完成
3.算法设计的要求
(1)算法特征
①算法的正确性
②可读性
③健壮性
④高效率和低存储量
【核心笔记】算法描述的工具
1.算法、语言、程序的关系
(1)算法:描述了数据对象的元素之间的关系(包括数据逻辑关系、存贮关系描述)。
(2)描述算法的工具:算法可用自然语言、框图或高级程序设计语言进行描述。
(3)程序是算法在计算机中的实现。
2.设计实现算法过程步骤
(1)找出与求解有关的数据元素之间的关系
(2)确定在某一数据对象上所施加运算
(3)考虑数据元素的存储表示
(4)选择描述算法的语言
(5)设计实现求解的算法,并用程序语言加以描述。
3.类描述算法的语言选择
(1)类语言:类语言是接近于高级语言而又不是严格的高级语言,具有高级语言的一般语句设施,撇掉语言中的细节,以便把注意力主要集中在算法处理步骤本身的描述上。
(2)对C语言作以下描述
赋值语句
(1)简单赋值
①〈变量名〉=〈表达式〉
②〈变量〉 ,
③〈变量〉--,
(2)串联赋值
〈变量1〉=〈变量2〉=〈变量3〉=…=〈变量k〉=〈表达式〉
(3)成组赋值
(<变量>,<变量2>,<变量3>,…<变量k〉=(<表达式1>,<表达式2>,<表达式3>,…<表达式k>)
〈数组名1〉[下标1][下标2]=〈数组名2〉[下标1][下标2]
(4)条件赋值
〈变量名〉=〈条件表达式〉?〈表达式1〉:〈表达式2〉
4.条件选择语句
5.循环语句
【核心笔记】对算法作性能评价
1.评价算法的标准
评价一个算法主要看这个算法所占用机器资源的多少,而这些资源中时间代价与空间代价是两个主要的方面,通常是以算法执行所需的机器时间和所占用的存储空间来判断一个算法的优劣。
2.性能评价
(1)定义:对问题规模与该算法在运行时所占的空间S与所耗费的时间T给出一个数量关系的评价。
(2)问题规模N—对不同的问题其含义不同
①对矩阵是阶数
②对多项式运算是多项式项数
③对图是顶点个数
④对集合运算是集合中元素个数
3.有关数量关系计算
(1)数量关系评价体现在时间——算法在机器中所耗费时间。
(2)数量关系评价体现在空间——算法在机器中所占存储量。
①关于算法执行时间
②语句频度
③算法的时间复杂度
④数据结构中常用的时间复杂度频率计数
⑤最坏时间复杂度
⑥算法的空间复杂度
4.关于算法执行时
(1)定义
一个算法的执行时间大致上等于其所有语句执行时间的总和,对于语句的执行时间是指该条语句的执行次数和执行一次所需时间的乘积。
(2)分析
不是针对实际执行时间的精确地算出算法执行具体时间,而是针对算法中语句的执行次数做出估计,从中得到算法执行时间的信息。
5.语句频度
定义:语句频度是指该语句在一个算法中重复执行的次数。
6.算法的时间复杂度
算法的时间复杂度,即是算法的时间量度记做:T(n)=O(f(n))
7.常用的时间复杂度频率计数
(1)数据结构中常用的时间复杂度频率计数有7个
①O(1)常数型O(n)线性型O(n2)平方型
②O(n3)立方型O(2n)指数型O(log2n)对数型
③O(nlog2n)二维型
(2)按时间复杂度由小到大排列的频率表
8.最坏时间复杂度
定义:讨论算法在最坏情况下的时间复杂度,即分析最坏情况下以估计出算法执行时间的上界。
9.算法的空间复杂度
定义:用空间复杂度作为算法所需存储空间的量度,记做:S(n)=O(f(n))。
【核心笔记】数据结构与C语言表示
1.数据结构与程序设计的关联性
问题描述:欲求1名学生10次C语言程序设计的测试成绩总分与平均分。其中10次测验的成绩分别为:80,85,77,56,68,83,90,92,80,98。
程序示例1-1:
2.结构化程序设计与函数的模块化
(1)结构化程序设计:是为使程序具有合理的结构,以保证程序正确性而规定的一套程序设计的方法。
(2)程序设计的实质:算法 数据结构=程序
即“程序是在数据的特定表示方式的基础上,对抽象算法的具体描述”。
程序结构=控制结构 数据结构
①结构化程序设计目的
通过设计结构良好的程序,以程序的静态良好结构保证程序动态执行的正确性,使程序易理解、易调试、易维护,以提高软件开发的效率,减少出错率。
②结构化程序设计的构成单元
任何程序都可由顺序、选择、重复三种基本控制结构来组成。
③结构化程序设计方法
a.“自顶向下,逐步求精”的设计思想
b.“独立功能,一个入口,一个出口“的模块化结构
c.“仅用三种基本控制结构”的设计原则
3.面向对象与抽象数据类型
(1)面向对象的概念:面向对象=对象 类 继承 通信
对象:指在应用问题中出现的各种实体、事件、规格说明等
类:具有相同属性和服务的对象
继承:是面向对象方法的最有特色的方面
面向对象程序设计的特点是封装性、继承性和多态性
与数据结构密切相关的是定义在数据结构上的一组操作。
①基本操作主要有
a.插入:在数据结构中的指定位置上增添新的数据元素
b.删除:删去数据结构中某个指定数据元素
c.更新:改变数据结构中某个元素的值,在概念上等价于删除和插入操作的组合
d.查找:在数据结构中寻找满足某个特定要求的数据元素(的位置和值)
e.排序:(在线性结构中)重新安排数据元素之间的逻辑顺序关系,使数据元素按值由小到大或由大到小的次序排列
结构化与面向对象开发方法的不同点。结构化的开发方法:是面向过程的开发方法,首先着眼于系统要实现的功能面向对象的开发方法:首先着眼于应用问题所涉及的对象,包括对象、对象属性和要求的操作,从而建立对象结构和为解决问题需要执行的时间序列。
(2)抽象数据类型与问题求解方法
定义:抽象数据类型(简称ADT)是指基于一类逻辑关系的数据类型以及定义在这个类型之上的一组操作。
一个抽象数据类型确定了一个模型,但将模型的实现细节隐藏起来;它定义了一组运算,但将运算的实现过程隐藏起来。
用抽象数据类型的概念来指导问题的求解过程
(3)数据的抽象
语言中十进制表示的数据98.65、9.6E3等,它们是二进制数据的抽象;
高级语言中,给出更高一级的数据抽象,如整型、实型、字符型等,
还可以进一步定义更高级的数据抽象,如各种表、队、栈、树、图、窗口、管理器等复杂的抽象数据类型。
(4)抽象数据类型
线性表的抽象数据类型的描述:
数据元素所有ai属于同一数据对象,i=1,2,……,nn≥0;
逻辑结构所有数据元素ai(i=1,2,…,n-1)存在次序关系
(5)抽象数据类型实现
①实现的三种方法
a.传统的面向过程的程序设计
b.“包”、“模型”的设计方法
c.面向对象的程序设计(Object Oriented Programming,简称OOP)
(6)ADT的表示与实现
①ADT的定义
ADT<ADT名>
{数据对象:<数据对象的定义>
结构关系:<结构关系的定义>
基本操作:<基本操作的定义>
}ADT<ADT名>
②基本操作的定义格式为
<操作名称>(参数表)
操作前提:<操作前提描述>
操作结果:<操作结果描述>
③关于参数传递
参数表中的参数有值参和变参两种。
用标准C语言表示和实现ADT描述时,主要有两个方面
a.通过结构体将int、float等固有类型组合到一起,构成一个结构类型,再用typedef为该类型或该类型指针重新起一个名字。
b.用C语言函数实现各操作
4.算法描述规范与设计风格
(1)算法表示格式与函数模块化算法表示格式
[函数返回值类型]函数名([形式参数及说明])
{内部数据说明;执行语句组;}/*函数名*/
函数的模块化
[包含文件语句]
[宏定义语句]
[自定义类型语句]
[所有子函数的原型说明]
[子函数1定义]
[子函数n定义]
[主函数定义]
(2)算法描述要点
①加上必要的注释注释形式可以用/*字符串*/
②避免函数返回值隐含说明
③预定义常量和类型
a.使用有意义的函数名与变量名
b.避免可能出现的二义性表达
c.规范多分支转向
d.简化输入、输出表述
④注意不同的退出语句区别
a.return<表达式>或return:用于函数结束。
b.break语句:可用在循环语句或switch语句中结束循环过程或跳出情况语句。
c.continue语句:可用在循环语句中结束本次循环过程,进入下一次循环过程。
d.exit语句:表示出现异常情况时,控制退出函数。
(3)与参数传递的相关技术
①变量的作用域
全局变量:程序中所有函数都可以访问的量
局部变量:只能在该函数中访问的量。
②参数传递方式
参数传递是函数之间进行信息通讯的重要渠道。其参数传递的主要方式有传值和传地址两类。函数参数表中的参数有两种:第一种参数只为操作提供待处理数据,又称值参;第二种参数既能为操作提供待处理数据,又能返回操作结果,也称变量参数。
③关于参数传递示例源程序
(4)函数结果的带出方式
①三种带出方式:全程量、函数返回值、传址参数
a.通过参数表的参数传递是一种参数显式传递方式,而通过全局变量是一种隐式参数传递,一个函数中对全局变量的改变会影响其它程序的调用,使用全局变量必须注意这个问题。
b.若函数结果需要带出多个值,该怎样实现?可以采用①全局变量方式带出,②通过地址传递带出(数组方式、结构体方式、指针方式)两类方式之一来实现。
②全局变量方式
a.一个全局变量方式带出的例子
b.数组方式带出的例子
c.结构体方式带出的例子
d.指针方式带出的例子
【核心笔记】关于学习数据结构
1.数据结构课程地位
数据结构与其它课程关系图
2.数据结构课程学习特点
(1)教学目标
学会分析数据对象的特征,掌握数据组织方法和计算机的表示方法,以便为应用所涉及数据选择适当的逻辑结构、存储结构及相应算法,初步掌握算法时间空间分析的技巧,培养良好的程序设计技能。
(2)学习方法
学习数据结构,必须经过大量的实践,在实践中体会构造性思维方法,掌握数据组织与程序设计的技术。
第2章 线性表
节:线性表的概念及运算
1.线性表的逻辑结构
(1)线性表的定义:线性表(LinearList)是由n(n≥0)个类型相同的数据元素a1,a2,…,an组成的有限序列,记做(a1,a2,…,ai-1,ai,ai 1,…,an)。
①数据元素之间是一对一的关系,即每个数据元素最多有一个直接前驱和一个直接后继。
②线性表的逻辑结构图为:
(2)线性表的特点
①同一性:线性表由同类数据元素组成,每一个ai必须属于同一数据对象。
②有穷性:线性表由有限个数据元素组成,表长度就是表中数据元素的个数。
③有序性:线性表中相邻数据元素之间存在着序偶关系<ai,ai 1>。
2.线性表的抽象数据类型定义
(1)抽象数据类型定义:
ADTLinearList{
数据元素:D={ai|ai∈D0,i=1,2,…,n n≥0,D0为某一数据对象}
关系:S={<ai,ai 1>|ai,ai 1∈D0,i=1,2,…,n-1}
基本操作:
①InitList(L)操作前提:L为未初始化线性表。
操作结果:将L初始化为空表。
②DestroyList(L)操作前提:线性表L已存在。
操作结果:将L销毁。
③ClearList(L)操作前提:线性表L已存在。
操作结果:将表L置为空表。
【核心笔记】线性表的顺序存储
1.线性表的顺序存储结构
(1)顺序存储结构的定义
①线性表的顺序存储是指用一组地址连续的存储单元依次存储线性表中的各个元素,使得线性表中在逻辑结构上相邻的数据元素存储在相邻的物理存储单元中,即通过数据元素物理存储的相邻关系来反映数据元素之间逻辑上的相邻关系。采用顺序存储结构的线性表通常称为顺序表。
②假设线性表中每个元素占k个单元,第一个元素的地址为loc(a1),则第k个元素的地址为:
loc(ai)=loc(a1) (i-1)×k
(2)顺序存储结构示意图
(3)顺序存储结构的C语言定义
#define maxsize=线性表可能达到的最大长度;
typedef struct
{ ElemType elem[maxsize]; /* 线性表占用的数组空间*/
int last; /*记录线性表中最后一个元素在数组elem[ ]
中的位置(下标值),空表置为-1*/}SeqList;
注意区分元素的序号和数组的下标,如a1的序号为1,而其对应的数组下标为0。
2.线性表顺序存储结构的基本运算
(1)线性表的基本运算:
①查找操作
②插入操作
③删除操作
④顺序表合并算法
(2)查找操作
线性表的两种基本查找运算
①按序号查找GetData(L,i):要求查找线性表L中第i个数据元素,其结果是L.elem[i-1]或L->elem[i-1]。
②按内容查找Locate(L,e):要求查找线性表L中与给定值e相等的数据元素,其结果是:若在表L中找到与e相等的元素,则返回该元素在表中的序号;若找不到,则返回一个“空序号”,如-1。
线性表的查找运算算法描述为:
(3)线性表的查找运算
intLocate(SeqListL,ElemTypee)
{ i=0; /*i为扫描计数器,初值为0,即从第一个元素开始比较*/
while((i<=L.last)&&(L.elem[i]!=e))i ;
/*顺序扫描表,直到找到值为key的元素,或扫描到表尾而没找到*/
If (i<=L.last)
return(i) ;/*若找到值为e的元素,则返回其序号*/
else
return(-1);/*若没找到,则返回空序号*/
}
(4)插入操作
线性表的插入运算是指在表的第i(1≤i≤n 1)个位置,插入一个新元素e,使长度为n的线性表(e1,…,ei-1,ei,…,en)变成长度为n 1的线性表(e1,…,ei-1,e,ei,…,en)。
(5)插入算法示意图
已知:线性表(4,9,15,28,30,30,42,51,62),需在第4个元素之前插入一个元素“21”。则需要将第9个位置到第4个位置的元素依次后移一个位置,然后将“21”插入到第4个位置,
(6)插入运算
int InsList(SeqList *L,int i,ElemType e)
{ int k;
if( (i<1) || (i>L->last 2) ) /*首先判断插入位置是否合法*/
{ printf(“插入位置i值不合法”);return(ERROR); }
if(L->last>=maxsize-1)
{ printf(“表已满无法插入”); return(ERROR); }
for(k=L->last;k>=i-1;k--) /*为插入元素而移动位置*/
L->elem[k 1]=L->elem[k];
L->elem[i-1]=e; /*在C语言中数组第i个元素的下标为i-1*/
L->last ;
return(OK);
}
(7)删除操作
线性表的删除运算是指将表的第i(1≤i≤n)个元素删去,使长度为n的线性表(e1,…,ei-1,ei,ei 1,…,en),变成长度为n-1的线性表(e1,…,ei-1,ei 1,…,en)。
算法思路示意
算法实现
(8)删除算法示意
将线性表(4,9,15,21,28,30,30,42,51,62)中的第5个元素删除。
(9)删除算法
int DelList(SeqList *L,int i,ElemType *e)
/*在顺序表L中删除第i个数据元素,并用指针参数e返回其值*/
{ int k;
if((i<1)||(i>L->last 1))
{ printf(“删除位置不合法!”); return(ERROR); }
*e= L->elem[i-1]; /* 将删除的元素存放到e所指向的变量中*/
for(k=i;i<=L->last;k )
L->elem[k-1]= L->elem[k]; /*将后面的元素依次前移*/
L->last--;
return(OK);
(10)合并算法
①已知:有两个顺序表LA和LB,其元素均为非递减有序排列,编写一个算法,将它们合并成一个顺序表LC,要求LC也是非递减有序排列。
②算法思想:设表LC是一个空表,为使LC也是非递减有序排列,可设两个指针i、j分别指向表LA和LB中的元素,若LA.elem[i]>LB.elem[j],则当前先将LB.elem[j]插入到表LC中,若LA.elem[i]≤LB.elem[j],当前先将LA.elem[i]插入到表LC中,如此进行下去,直到其中一个表被扫描完毕,然后再将未扫描完的表中剩余的所有元素放到表LC中。
③算法实现
此处连接算法演示
(11)顺序表合并算法实现
void merge(SeqList *LA, SeqList *LB, SeqList *LC)
{ i=0;j=0;k=0;
while(i<=LA->last&&j<=LB->last)
if(LA->elem[i]<=LB->elem[j])
{ LC->elem[k]= LA->elem[i]; i ; k ; }
Else
{ LC->elem[k]=LB->elem[j]; j ; k ; }
while(i<=LA->last) /*当表LA长则将表LA余下的元素赋给表LC*/
{ LC->elem[k]= LA->elem[i]; i ; k ; }
while(j<=LB->last) /*当表LB长则将表LB余下的元素赋给表LC*/
{ LC->elem[k]= LB->elem[j]; j ; k ; }
LC->last=LA->last LB->last;
}
(12)顺序存储结构的优点和缺点
优点:
①无需为表示结点间的逻辑关系而增加额外的存储空间;
②可方便地随机存取表中的任一元素。
缺点:
①插入或删除运算不方便,除表尾的位置外,在表的其它位置上进行插入或删除操作都必须移动大量的结点,其效率较低;
②由于顺序表要求占用连续的存储空间,存储分配只能预先进行静态分配。因此当表长变化较大时,难以确定合适的存储规模。
【核心笔记】线性表的链式存储
(1)链表定义:采用链式存储结构的线性表称为链表。
(2)现在我们从两个角度来讨论链表:
①从实现角度看,链表可分为动态链表和静态链表;
②从链接方式的角度看,链表可分为单链表、循环链表和双链表。
1.单链表
(1)结点(Node)为了正确地表示结点间的逻辑关系,必须在存储线性表的每个数据元素值的同时,存储指示其后继结点的地址(或位置)信息,这两部分信息组成的存储映象叫做结点(Node)。
(2)单链表:链表中的每个结点只有一个指针域,我们将这种链表称为单链表。
单链表包括两个域:数据域用来存储结点的值;指针域用来存储数据元素的直接后继的地址(或位置)。
(3)头指针:指向链表头结点的指针。
(4)单链表的示例图
(5)带头结点的单链表示意图
有时为了操作的方便,还可以在单链表的第一个结点之前附设一个头结点。
①带头结点的空单链表
②带头结点的单链表
(6)单链表的存储结构描述
typedef struct Node / * 结点类型定义 * /
{ ElemType data;
struct Node * next;
}Node, *LinkList;/* LinkList为结构指针类型*/
2.单链表上的基本运算
(1)线性表的基本运算:
①建立单链表
a.头插法建表
算法描述:从一个空表开始,重复读入数据,生成新结点,将读入数据存放到新结点的数据域中,然后将新结点插入到当前链表的表头结点之后,直至读入结束标志为止。
b.头插法建表算法
Linklist CreateFromHead()
{ LinkList L; Node *s; int flag=1;
/* 设置一个标志,初值为1,当输入“$”时,flag为0,建表结束*/
L=(Linklist)malloc(sizeof(Node));/*为头结点分配存储空间*/
L->next=NULL;
while(flag)
{ c=getchar();
if(c!=’$’) /*为读入的字符分配存储空间*/
{ s=(Node*)malloc(sizeof(Node)); s->data=c;
s->next=L->next; L->next=s; }
else flag=0;
}
c.尾插法建表
d.尾插法建表算法
Linklist CreateFromTail() /*将新增的字符追加到链表的末尾*/
{ LinkList L; Node *r, *s; int flag =1;
L=(Node * )malloc(sizeof(Node));/*为头结点分配存储空间*/
L->next=NULL; r=L; /*r指针始终动态指向链表的当前表尾*/
while(flag)/*标志,初值为1。输入“$”时flag为0,建表结束*/
{ c=getchar();
if(c!=’$’)
{ s=(Node*)malloc(sizeof(Node)); s->data=c;
r->next=s; r=s }
else { flag=0; r->next=NULL; }
}
}
(2)单链表查找.
①按序号查找
算法描述:设带头结点的单链表的长度为n,要查找表中第i个结点,则需要从单链表的头指针L出发,从头结点(L->next)开始顺着链域扫描,用指针p指向当前扫描到的结点,初值指向头结点(pL->next),用j做记数器,累计当前扫描过的结点数(初值为0),当j=i时,指针p所指的结点就是要找的第i个结点。算法实现,算法演示。
②按序号查找算法实现
/ * 在带头结点的单链表L中查找第i个结点,若找到(1≤i≤n),则返回该结点的存储位置; 否则返
NULL * /
Node * Get(LinkList L, int i)
{ Node *p;
p=L;j=0; / * 从头结点开始扫描 * /
while ((p->next!=NULL)&&(j<i)
{ p=p->next; j ; / * 扫描下一结点 * /
} / * 已扫描结点计数器 * /
if(i= =j)return p; / * 找到了第i个结点 * /
else return NULL; / * 找不到,i≤0或i>n * /
}
③按值查找
算法描述:按值查找是指在单链表中查找是否有结点值等于e的结点,若有的话,则返回首次找到的其值为e的结点的存储位置,否则返回NULL。查找过程从单链表的头指针指向的头结点出发,顺着链逐个将结点的值和给定值e作比较。算法实现,算法演示。
④按值查找算法实现
/ * 在带头结点的单链表L中查找其结点值等于key的结点,若找到则返回该结点的位置p,否则返
NULL * /
Node *Locate( LinkList L,ElemType key)
{ Node *p;
p=L->next; / * 从表中第一个结点比较 * /
while (p!=NULL)
if (p->data!=key)
p=p->next;
else break; / * 找到结点key,退出循环 * /
return p;
}
(3)单链表插入操作
①算法描述:要在带头结点的单链表L中第i个数据元素之前插入一个数据元素e,需要首先在单链表中找到第i-1个结点并由指针pre指示,然后申请一个新的结点并由指针s指示,其数据域的值为e,并修改第i-1个结点的指针使其指向s,然后使s结点的指针域指向第i个结点。
②单链表插入操作算法实现
void InsList(LinkList L,int i,ElemType e)\
{ /*在带头结点的单链表L中第i个结点之前插入值为e的新结点。 */
Node *pre,*s; pre=L; int k=0;
while(pre!=NULL&&k<i-1)
/*先找到第i-1个数据元素的存储位置,使指针Pre指向它*/
{ pre=pre->next; k=k 1; }
if(k!=i-1)
{ printf(“插入位置不合理!”); return; }
s=(Node*)malloc(sizeof(Node)); /*为e申请一个新的结点*/
s->data=e; /*将待插入结点的值e赋给s的数据域*/
s->next=pre->next; pre->next=s;
}
(4)单链表删除
①算法描述:
欲在带头结点的单链表L中删除第i个结点,则首先要通过计数方式找到第i-1个结点并使p指向第i-1个结点,而后删除第i个结点并释放结点空间。
②单链表删除算法实现
void DelList(LinkList L,int i,ElemType *e)
/*在带头结点的单链表L中删除第i个元素,并保存其值到变量*e中*/
{
Node *p,*r; p=L; int k =0;
while(p->next!=NULL&&k<i-1) /*寻找被删除结点i的前驱结点*/
{ p=p->next; k=k 1; }
if(k!=i-1) /* 即while循环是因为p->next=NULL而跳出的*/
{ printf(“删除结点的位置i不合理!”); return ERROR; }
r=p->next; p->next=p->next->next /*删除结点r*/
free(r); /*释放被删除的结点所占的内存空间*/
}
3.算法应用示例
(1)求单链表的长度
算法描述:可以采用“数”结点的方法来求出单链表的长度,用指针p依次指向各个结点,从第一个素开始“数”,一直“数”到最后一个结点(p->next=NULL)。
int ListLength(LinkList L) /*L为带头结点的单链表*/
{ Node *p; p=L->next;
j=0; /*用来存放单链表的长度*/
while(p!=NULL)
{ p=p->next; j ; }
return j;
}
①两个有序单链表的合并
有两个单链表LA和LB,其元素均为非递减有序排列,编写一个算法,将它们合并成一个单链表LC,要求LC也是非递减有序排列。要求:利用新表LC利用现有的表LA和LB中的元素结点空间,而不需要额外申请结点空间。例如LA=(2,2,3),LB=(1,3,3,4),则LC=(1,2,2,3,3,3,4)。
②算法描述:要求利用现有的表LA和LB中的结点空间来建立新表LC,可通过更改结点的next域来重建新的元素之间的线性关系,为保证新表仍然递增有序,可以利用尾插入法建立单链表的方法,只是新建表中的结点不用malloc,而只需要从表LA和LB中选择合适的点插入到新表LC中即可。
(2)求两个集合的差
LinkList MergeLinkList(LinkList LA, LinkList LB)
/*将递增有序的单链表LA和LB合并成一个递增有序的单链表LC*/
{ Node *pa,*pb;
LinkList LC;
/*将LC初始置空表。pa和pb分别指向两个单链表LA和LB中的第一个结点,r初值为LC*/
pa=LA->next;
pb=LB->next;
LC=LA;
LC->next=NULL;r=LC; /*初始化操作*/
/*当两个表中均未处理完时,比较选择将较小值结点插入到新表LC中。*/
while(pa!=NULL&&pb!=NULL)
{if(pa->data<=pb->data)
{r->next=pa;r=pa;pa=pa->next;}
Else
{r->next=pb;r=pb;pb=pb->next;}
}
if(pa) /*若表LA未完,将表LA中后续元素链到新表LC表尾*/
r->next=pa;
else /*否则将表LB中后续元素链到新表LC表尾*/
r->next=pb;
free(LB);
return(LC);
} /* MergeLinkList */
4.循环链表
(1)循环链表(Circular Linked List)是一个首尾相接的链表。
(2)特点:将单链表最后一个结点的指针域由NULL改为指向头结点或线性表中的第一个结点,就得到了单链形式的循环链表,并称为循环单链表。在循环单链表中,表中所有结点被链在一个环上。
带头结点循环单链表示意图。
(3)带头结点的循环单链表示意图
(4)循环单链表合并为一个循环单链表
已知:有两个带头结点的循环单链表LA、LB,编写一个算法,将两个循环单链表合并为一个循环单链表,其头指针为LA。
算法思想:先找到两个链表的尾,并分别由指针p、q指向它们,然后将第一个链表的尾与第二个表的第一个结点链接起来,并修改第二个表的尾Q,使它的链域指向第一个表的头结点。
(5)循环单链表合并算法实现
LinkListmerge_1(LinkListLA,LinkListLB)
/*此算法将两个链表的首尾连接起来*/
{ Node *p, *q; p=LA; q=LB;
while (p->next!=LA) p=p->next; /*找到表LA的表尾*/
while (q->next!=LB) q=q->next; /*找到表LB的表尾*/
q->next=LA;/*修改表LB 的尾指针,使之指向表LA 的头结点*/
p->next=LB->next;/*修改表LA的尾指针,使之指向表LB 中的第一个结点*/
free(LB);
return(LA);
}
5.双向链表
(1)双向链表:在单链表的每个结点里再增加一个指向其前趋的指针域prior。这样形成的链表中就有两条方向不同的链,我们称之为双(向)链表(DoubleLinkedList)。
(2)双向链表的结构定义:
typedef struct Dnode
{ ElemType data;
struct DNode *prior,*next;
} DNode, * DoubleList;
(3)双链表的结点结构
(4)双向循环链表示意图
(5)双向链表的前插操作
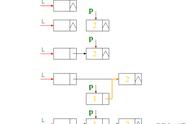
算法描述:欲在双向链表第i个结点之前插入一个的新的结点,则指针的变化情况如图所示。
(6)双向链表的前插操作算法实现
void DlinkIns(DoubleList L,int i,ElemType e)
{ DNode *s,*p;
… /*首先检查待插入的位置i是否合法*/
… /*若位置i合法,则让指针p指向它*/
s=(DNode*)malloc(sizeof(DNode));
if (s)
{ s->data=e;
s->prior=p->prior; p->prior->next=s;
s->next=p; p->prior=s; return TRUE;
} else return FALSE;
}
(7)双向链表的删除操作
算法描述:欲删除双向链表中的第i个结点,则指针的变化情况如图所示。
(8)双向链表的删除操作算法实现
int DlinkDel(DoubleList L,int i,ElemType *e)
{ DNode *p;
… /*首先检查待插入的位置i是否合法*/
… /*若位置i合法,则让指针p指向它*/
*e=p->data;
p->prior->next=p->next;
p->next->prior=p->prior;
free(p);
return TRUE;
}
6.静态链表
(1)基本概念:游标实现链表的方法:定义一个较大的结构数组作为备用结点空间(即存储池)。当申请结点时,每个结点应含有两个域:data域和next域。data域存放结点的数据信息,next域为游标指示器,指示后继结点在结构数组中的相对位置(即数组下标)。数组的第0个分量可以设计成表的头结点,头结点的next域指示了表中第一个结点的位置,为0表示静态单链表的结束。我们把这种用游标指示器实现的单链表叫做静态单链表(StaticLinkedList)。静态链表的结构定义,静态链表的插入和删除操作示例。
(2)基本操作:
初始化、分配结点与结点回收、前插操作、删除。
①静态链表的结构定义
#define Maxsize= 链表可能达到的最大长度
typedef struct
{
ElemType data;
int cursor;
}Component, StaticList[Maxsize];
②静态链表的插入和删除操作示例
已知:线性表a,b,c,d,f,g,h,i),Maxsize=11
(3)静态链表初始化
算法描述:初始化操作是指将这个静态单链表初始化为一个备用静态单链表。设space为静态单链表的名字,av为备用单链表的头指针,其算法如下:
void initial(StaticList space,int *av)
{ int k;
space[0]->cursor=0;/*设置静态单链表的头指针指向位置0*/
for(k=0;k<Maxsize-1;k )
space[k]->cursor=k 1; /*连链*/
space[Maxsize-1] . cursor =0; /*标记链尾*/
*av=1; /*设置备用链表头指针初值*/
}
(4)静态链表分配结点与结点回收
①分配结点
int getnode(int *av)/*从备用链表摘下一个结点空间,分配给待插入静态链表中的元素*/
{ int i=*av;
*av=space[*av].cur;
return i;
}
②结点回收
void freenode(int *av,int k) /*将下标为 k的空闲结点插入到备用链表*/
{ space[k].cursor=*av; *av=k; }
【核心笔记】一元多项式的表示及相加
(1)一元多项式可按升幂的形式写成:
(2)Pn(x)=p0 p1xe1 p2xe2 … pnxen,
(3)其中ei为第i项的指数,pi是指数ei的项的系数,(且1≤e1≤e2≤…≤en)
(4)假设Qm(x)是一个一元多项式,则它也可以用一个线性表Q来表示。即:
Q=(q0,q1,q2,…,qm)
(5)若假设m<n,则两个多项式相加的结果Rn(x)=Pn(x) Qm(x),也可以用线性表R来表示:R=(p0 q0,p1 q1,,p2 q2,…,pm qm,pm 1,…,pn)
1.一元多项式的存储
(1)一元多项式Pn(x)的顺序表示有两种。
①只存储该一元多项式各项的系数,每个系数所对应的指数项则隐含在存储系数的顺序表的下标中。即p[0]存系数p0,对应为x0的系数,p[1]存系数p1,对应为x1的系数,……p[n]存系数pn,对应为xn的系数。采用这种存储方法使得多项式的相加运算的算法定义十分简单,只需将下标相同的单元的内容相加即可。适合于存储表示非零系数多的多项式。
②采用只存储非零项的方法,此时每个非零项需要存储:非零项系数和非零项指数。适合存储表示非零项少的多项式。
图2.19一元多项式只存非零项存储示意图
2.一元多项式的链式存储表示
在链式存储中,对一元多项式只存非零项,则该多项式中每一非零项由两部分构成(指数项和系数项),用单链表存储表示的结点结构为:
用单链表存储多项式的结点结构如下:
struct Polynode
{
int coef;
int exp;
Polynode *next;
} Polynode , * Polylist;
3.建立一元多项式链式存储的算法
(1)算法思想:通过键盘输入一组多项式的系数和指数,用尾插法建立一元多项式的链表。以输入系数0为结束标志,并约定建立多项式链表时,总是按指数从小到大的顺序排列。
(2)算法描述
Polylist polycreate()
{ Polynode *head, *rear, *s; int c,e;
rear=head =(Polynode *)malloc(sizeof(Polynode));
/*建立多项式的头结点, rear 始终指向单链表的尾*/
scanf(“%d,%d”,&c,&e);/*键入多项式的系数和指数项*/
while(c!=0) /*若c=0,则代表多项式的输入结束*/
{ s=(Polynode*)malloc(sizeof(Polynode)); /*申请新的结点*/
s->coef=c ; s->exp=e ;rear->next=s ; /*在当前表尾做插入*/
rear=s; scanf(“%d,%d”,&c,&e); }
rear->next=NULL;/*将表的最后一个结点的next置NULL,以示表结束*/
return(head);}
4.一元多项式的单链表表示示意图
说明:图示分别为多项式
A(x)=7 3x 9x8 5x17
B(x)=8x 22x7-9x8
5.两个一元多项式相加
(1)运算规则:两个多项式中所有指数相同的项的对应系数相加,若和不为零,则构成“和多项式”中的一项;所有指数不相同的项均复抄到“和多项式”中。算法实现,算法演示
①若p->exp<q->exp,则结点p所指的结点应是“和多项式”中的一项,令指针p后移;
②若p->exp>q->exp,则结点q所指的结点应是“和多项式”中的一项,将结点q插入在结点p之前,且令指针q在原来的链表上后移;
③若p->exp=q->exp,则将两个结点中的系数相加,当和不为零时修改结点p的系数域,释放q结点;若和为零,则和多项式中无此项,从A中删去p结点,同时释放p和q结点。
6.两个多项式相加算法实现
void polyadd(Polylist polya;Polylist polyb)
{
……/* p和q分别指向polya和polyb链表中的当前计算结点*/
……/* pre指向和多项式链表中的尾结点*/
while p!=NULL && q!=NULL)
{ if (p->exp< q->exp)
{ …/*将p结点加入到和多项式中*/}
else if ( p->exp= =q->exp)
{ …/*若指数相等,则相应的系数相加。若系数为0则删除p,q节点*/}
else{ …/*将q结点加入到和多项式中*/}
}
…../*将多项式polya或polyb中剩余的结点加入到和多项式中*/
}
【核心笔记】顺序表和链表的比较
(1)基于空间的考虑
(2)基于时间的考虑
(3)基于语言的考虑
(4)线性表链式存储方式的比较
第3章 栈和队列
节:栈
1.栈的定义
栈作为一种限定性线性表,是将线性表的插入和删除运算限制为仅在表的一端进行。通常将表中允许进行插入、删除操作的一端称为栈顶(Top),表的另一端被称为栈底(Bottom)。当栈中没有元素时称为空栈。栈的插入操作被形象地称为进栈或入栈,删除操作称为出栈或退栈。
栈的抽象数据类型定义
数据元素:可以是任意类型的数据,但必须属于同一个数据对象。
关系:栈中数据元素之间是线性关系
基本操作:
(1)InitStack(S)
(2)ClearStack(S)
(3)IsEmpty(S)
(4)sFull(S)
(5)Push(S,x)
(6)Pop(S,x)
(7)GetTop(S,x)
2.栈的表示和实现
栈在计算机中主要有两种基本的存储结构:顺序存储结构和链式存储结构。
顺序存储的栈为顺序栈;
链式存储的栈为链栈。
顺序栈基本操作的实现
(1)初始化
(2)进栈
(3)出栈
(4)取栈顶元素
两栈共享技术(双端栈):
主要利用了栈“栈底位置不变,而栈顶位置动态变化”的特性。首先为两个栈申请一个共享的一维数组空间S[M],将两个栈的栈底分别放在一维数组的两端,分别是0,M-1。
共享栈的空间示意为:top[0]和top[1]分别为两个栈顶指示器。
两栈共享的数据结构定义
(1)两栈共享的初始化操作算法
(2)两栈共享的进栈操作算法
(3)两栈共享的出栈操作算法
3.链栈
链栈是采用链表作为存储结构实现的栈。为便于操作,采用带头结点的单链表实现栈。由于栈的插入和删除操作仅限制在表头位置进行,所以链表的表头指针就作为栈顶指针。链栈的示意图为:
top为栈顶指针,始终指向当前栈顶元素前面的头结点。若top->next=NULL,则代表空栈。
(1)多栈运算
将多个链栈的栈顶指针放在一个一维指针数组中来统一管理,从而实现同时管理和使用多个栈。
用c语言定义
①第i号栈的进栈操作②第i号栈元素的出栈操作
4.栈与递归的实现
递归:在定义自身的同时又出现了对自身的调用。
直接递归函数:如果一个函数在其定义体内直接调用自己,则称直接递归函数。
间接递归函数:如果一个函数经过一系列的中间调用语句,通过其它函数间接调用自己,则称间接递归函数。
(1)具有递归特性的问题
①递归定义的数学函数
②递归数据结构的处理
③递归求解方法
圆盘移动时必须遵循下列规则:
①每次只能移动一个圆盘;
②圆盘可以插在X,Y和Z中的任何一个塔座上;
③任何时刻都不能将一个较大的圆盘压在较小的圆盘之上。
算法思想:
当n=1时,问题比较简单,只要将编号为1的圆盘从座X直接移动到塔座Z上即可;当n>1时,需利用塔座Y作辅助塔座,若能设法将压在编号为n的圆盘上的n-1个圆盘从塔座X(依照上述原则)移至塔座Y上,则可先将编号为n的圆盘从塔座X移至塔座Z上,然后再将塔座Y上的n-1个圆盘(依照上述原则)移至塔座Z上。而如何将n-1个圆盘从一个塔座移至另一个塔座问题是一个和原问题具有相同特征属性的问题,只是问题的规模小于1,因此可以用同样方法求解。
递归方法的优点:
①对问题描述简洁
②结构清晰
③程序的正确性容易证明
设计递归算法的方法
递归算法就是在算法中直接或间接调用算法本身的算法。
使用递归算法的前提有两个:
①原问题可以层层分解为类似的的子问题,且子问题比原问题的规模更小。
②规模最小的子问题具有直接解。
设计递归算法的方法
①寻找分解方法
②设计递归出口
(2)递归过程的实现
递归进层(i→i 1层)系统需要做三件事:
①保留本层参数与返回地址;
②为被调用函数的局部变量分配存储区,给下层参数赋值;
③将程序转移到被调函数的入口。
递归退层(i←i 1层)系统也应完成三件工作:
①保存被调函数的计算结果;
②释放被调函数的数据区,恢复上层参数;
③依照被调函数保存的返回地址,将控制转移回调用函数。
(3)递归算法到非递归算法的转换
递归算法具有两个特性:
①递归算法是一种分而治之、把复杂问题分解为简单问题的求解问题方法,对求解某些复杂问题,递归算法的分析方法是有效的。
②递归算法的效率较低。
a.消除递归的原因:
有利于提高算法时空性能;无应用递归语句的语言设施环境条件;递归算法是一次执行完
消除递归方法有两类:
一类是简单递归问题的转换,对于尾递归和单向递归的算法,可用循环结构的算法替代。
另一类是基于栈的方式,即将递归中隐含的栈机制转化为由用户直接控制的明显的栈。
b.简单递归的消除
单向递归
单向递归是指递归函数中虽然有一处以上的递归调用语句,但各次递归调用语句的参数只和主调用函数有关,相互之间参数无关,并且这些递归调用语句处于算法的最后。
尾递归
尾递归是指递归调用语句只有一个,而且是处于算法的最后,尾递归是单向递归的特例。
【核心笔记】队列
1.队列的定义
队列:是另一种限定性的线性表,它只允许在表的一端插入元素,而在另一端删除元素,所以队列具有先进先出的特性。
在队列中,允许插入的一端叫做队尾(rear),允许删除的一端则称为队头(front)。
队列的抽象数据类型定义:
数据元素:可以是任意类型的数据,但必须属于同一个数据对象。
关系:队列中数据元素之间是线性关系。
基本操作:
(1)InitQueue(&Q):初始化操作
(2)IsEmpty(Q):判空操作
(3)IsFull(Q):判满操作
(4)EnterQueue(&Q,x):进队操作
(5)EnterQueue(&Q,x):进队操作
(6)GetHead(Q,&x):取队头元素操作
(7)ClearQueue(&Q):队列置空操作
(8)DestroyQueue(&Q):队列销毁操作
2.队列的表示和实现
队列的两种存储表示,顺序表示和链式表示。
(1)链队列:用链表表示的队列简称为链队列。
链队列的基本操作:
①初始化操作②入队操作③出队操作
(2)循环队列
循环队列是队列的一种顺序表示和实现方法。
循环队列的基本操作
①初始化操作
②入队操作
③出队操作
第4章 串
节:串的基本概念
1.串的基本概念
(1)串(String)是零个或多个字符组成的有限序列。
一般记为: S=‘a1a2…an’ (n≥0)
(2)其中S为串名,用单引号括起来的为串值, n为串的长度。
(3)子串:串中任意个连续的字符组成的子序列称为该串的子串。
(4)主串:包含子串的串相应地称为主串。
(5)空串: n=0时的串为空串
通常将字符在串中的序号称为该字符在串中的位置。
(6)空格串:由一个或多个称为空格的特殊字符组成的串。
串的抽象数据类型定义:
ADT String {
数据对象:D={ai| ai ∈CharacterSet,i=1,2,…,n; n≥0}
数据关系:R={<ai-1,ai>| ai-1,ai ∈D,i=2,…,n; n≥0}
基本操作:
① StrAsign(S,chars)
初始条件:chars是字符串常量
操作结果:生成一个值等于chars的串S
②StrInsert(S,pos,T)
初始条件:串S和T存在,1≤pos≤StrLength(S) 1
操作结果:在串S的第pos个字符之前插入串T
③StrDelete(S,pos,len)
初始条件: 串S存在,1≤pos≤StrLength(S) -len 1
操作结果: 从串S中删除第pos个字符起长度为len的子串
④StrCopy(S,T)
初始条件: 串S存在
操作结果:由串T复制得串S
⑤StrEmpty(S)
初始条件: 串S存在
操作结果:若串S为空串,则返回TRUE,否则返回FALSE
⑥StrCompare(S,T)
初始条件: 串S和T存在
操作结果:若S>T,则返回值>0;若S=T,则返回值=0;若S<T, 则返回值<0
⑦StrLength(S)
初始条件: 串S存在
操作结果:返回串S的长度,即串S中的元素个数
⑧StrClear(S)
初始条件: 串S存在
操作结果:将S清为空串
⑨StrCat(S,T)
初始条件: 串S和T存在
操作结果:将串T的值连接在串S的后面
⑩SubString(Sub,S,pos,len)
初始条件:串S存在,1≤pos≤StrLength(S)且1≤len≤StrLength(S)-pos 1
操作结果:用Sub返回串S的第pos个字符起长度为len的子串
⑪StrIndex(S,T,pos)
初始条件: 串S和T存在,T是非空串, 1≤pos≤StrLength(S)
操作结果:若串S中存在与串T相同的子串,则返回它在串S中第pos个字符之后第一次出现的位置;否则返回0
⑫StrReplace(S,T,V)
初始条件: 串S,T和V存在, 且T是非空串
操作结果:用V替换串S中出现的所有与T相等的不重叠子串
⑬StrDestroy(S)
初始条件: 串S存在
操作结果:销毁串S
【核心笔记】串的存储实现
1.定长顺序串
定长顺序串是将串设计成一种静态结构类型,串的存储分配是在编译时完成的。
(1)定长顺序串存储结构
#define MAXLEN 20
typedef struct { /*串结构定义*/
char ch[MAXLEN];
int len;
} SString;
2.定长顺序串基本操作的实现
(1)串插入函数
有三种情况:
①插入后串长(LA LC LB)≤MAXLEN,则将B后移LC个元素位置,再将C插入。
②插入后串长>MAXLEN且pos LC<MAXLEN,则B后移时会有部分字符被舍弃。
③插入后串长>MAXLEN且pos LC>MAXLEN,则 B的全部字符被舍弃(不需后移),并且C在插入时也有部分字符被舍弃。
顺序串插入函数算法
StrInsert(SString *s, int pos, SString t)
/*在串s中下标为pos的字符之前插入串t */
{ int i;
if (pos<0 || pos>s->len) return(0); /*插入位置不合法*/
if (s->len t.len<=MAXLEN) { /*插入后串长≤MAXLEN*/
for (i=s->len t.len-1;i>=t.len pos;i--)
s->ch[i]=s->ch[i-t.len];
for (i=0;i<t.len;i ) s->ch[i pos]=t.ch[i];
s->len=s->len t.len;
}
else if (pos t.len<=MAXLEN) {/*插入后串长>MAXLEN,但串t的字符序列可以全部插入*/
for (i=MAXLEN-1;i>t.len pos-1;i--) s->ch[i]=s->ch[i-t.len];
for (i=0;i<t.len;i ) s->ch[i pos]=t.ch[i];
s->len=MAXLEN;
}
else { /*插入后串长>MAXLEN,并且串t的部分字符也要舍弃
for (i=0;i<MAXLEN-pos;i ) s->ch[i pos]=t.ch[i];
s->len=MAXLEN;
}
return(1);
}
(2)串删除函数
StrDelete(SString *s, int pos, int len)
/*在串s中删除从下标pos起len个字符*/
{ int i;
if (pos<0 || pos>(s->len-len)) return(0); /*删除参数不合法*/
for (i=pos len;i<s->len;i )
s->ch[i-len]=s->ch[i]; /*从pos len开始至串尾依次向前移动,实现删除len个字符*/
s->len=s->len - len; /*s串长减len*/
return(1);
}
(3)串复制函数
StrCopy(SString *s, SString t)
/*将串t的值复制到串s中*/
{ int i;
for (i=0;i<t.len;i ) s->ch[i]=t.ch[i];
s->len=t.len;
}
(4)判空函数
StrEmpty(SString s)
/*若串s为空则返回1,否则返回0 */
{
if (s.len==0) return(1);
else return(0);
}
(5)串比较函数
StrCompare(SString s, SString t)
/*若串s和t相等则返回0;若s>t则返回正数;若s<t则返回负数*/
{ int i;
for (i=0;i<s.len&&i<t.len;i )
if (s.ch[i]!=t.ch[i]) return(s.ch[i] - t.ch[i]);
return(s.len - t.len);
}
(6)求串长函数
StrLength(SString s)
/* 返回串s的长度*/
{
return(s.len);
}
(7)清空函数
StrClear(SString *s)
/*将串s置为空串*/
{
s->len=0;
}
(8)连接函数
①连接后串长≤MAXLEN,则直接将B加在A的后面。
②连接后串长>MAXLEN且LA<MAXLEN,则B会有部分字符被舍弃。
③连接后串长>MAXLEN且LA=MAXLEN,则B的全部字符被舍弃(不需连接)。
串连接函数算法
StrCat(SString *s, SString t)
/*将串连接在串s的后面*/
{ int i, flag;
if (s->len t.len<=MAXLEN) /*连接后串长小于MAXLEN*/
{
for (i=s->len; i<s->len t.len; i )
s->ch[i]=t.ch[i-s->len];
s->len =t.len;
flag=1;
}
else if (s->len<MAXLEN) /*连接后串长大于MAXLEN,但串s的长度小于MAXLEN,
{ 即连接后串t的部分字符序列被舍弃*/
for (i=s->len;i<MAXLEN;i )
s->ch[i]=t.ch[i-s->len];
s->len=MAXLEN;
flag=0;
}
else flag=0; /* 串s的长度等于MAXLEN ,串t不被连接*/
return(flag);
}
(9)求子串函数
SubString(SString *sub, SString s, int pos, int len)
/*将串s中下标pos起len个字符复制到sub中*/
{ int i;
if (pos<0 || pos>s.len || len<1 || len>s.len-pos)
{ sub->len=0;
return(0);
}
else {
for (i=0; i<len; i )
sub->ch[i]=s.ch[i pos];
sub->len=len;
return(1);
}
}
(10)定位函数
T为目标串(主串),S为模式串(子串),在主串T中找子串S的过程为模式匹配(pattern matching)。用定位函数实现求子串T在主串S中从pos的位置开始第一次出现的位置序号,定位函数也叫串的模式匹配。
(11)串的简单模式匹配Brute-Force(布鲁特-福斯)算法
算法思想
简单的模式匹配算法是一种带回溯的匹配算法,算法的基本思想是:从主串S的第pos个字符开始,和模式串T的第一个字符开始比较,如果相等,就继续比较后续字符,如果不等,则从(回溯到)主串S的第pos 1个字符开始重新和模式串T比较,直到模式串T中的每一个字符和主串S中的一个连续字符子序列全部相等,则称匹配成功,返回和T中第一个字符相等的字符在主串T中的位置;或者主串中没有和模式串相等的字符序列,则称匹配不成功。
算法描述
实现时设i、j、start三个指示器:
i——指向主串T中当前比较的字符,起始指向T的首字符,此后,每比较一步,后移一步,一趟匹配失败时,回溯到该趟比较起点的下一位置。
j——指向子串S中当前比较的字符,起始指向S的首字符,此后,每比较一步,后移一步,一趟匹配失败时,回溯到S的首字符处。
start——记录每趟比较时在主串T中的起点,每趟比较后,后移一步,以便确定下一趟的起始位置。
顺序串的简单模式匹配(定位)函数算法
StrIndex(SString s,int pos, SString t)
/*求从主串s的下标pos起,串t第一次出现的位置,成功返回位置序号,不成功返回-1*/
{ int i, j, start;
if (t.len==0) return(0); /* 模式串为空串时,是任意串的匹配串 */
start=pos; i=start; j=0; /* 主串从pos开始,模式串从头(0)开始 */
while (i<s.len && j<t.len)
if (s.ch[i]==t.ch[j]) {i ; j ;} /* 当前对应字符相等时推进 */
else { start ; /* 当前对应字符不等时回溯 */
i=start; j=0; /* 主串从start 1开始,模式串从头(0)开始*/
}
if (j>=t.len) return(start); /* 匹配成功时,返回匹配起始位置 */
else return(-1); /* 匹配不成功时,返回-1 */
}
2.堆串
字符串包括串名与串值两部分,而串值采用堆串存储方法存储,串名用符号表存储。
堆串存储方法:仍以一组地址连续的存储单元存放串的字符序列,但它们的存储空间是在程序执行过程中动态分配的。系统将一个地址连续、容量很大的存储空间作为字符串的可用空间,每当建立一个新串时,系统就从这个空间中分配一个大小和字符串长度相同的空间存储新串的串值。
堆串存储表示:在C语言中,已经有一个称为“堆”的自由存储空间,并可用函数malloc()和函数free()完成动态存储管理。因此,我们可以直接利用C语言中的“堆”来实现堆串。此时堆串可定义如下:
typedef struct
{
char * ch;
int len;
} HString;
其中len域指示串的长度,ch域指示串的起始地址。
串名符号表:所有串名的存储映像构成一个符号表。借助此结构可以在串名和串值之间建立一个对应关系,称为串名的存储映像。
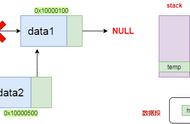
堆串的存储映象示例
a='a program',b='string ',c='process',free=23。
堆串的基本操作
(1)堆串赋值函数
StrAssign(HString *s,char *tval) /*将字符常量tval的值赋给串s */
{ int len,i=0;
if (s->ch!=NULL) free(s->ch);
while (tval[i]!='\0') i ;
len=i;
if (len)
{ s->ch=(char *)malloc(len);
if (s->ch==NULL) return(0);
for (i=0;i<len;i ) s->ch[i]=tval[i];
}
else s->ch=NULL; s->len=len;
return(1);
}
(2)堆串插入函数
StrInsert(HString *s,int pos,HString *t)
/*在串s中下标为pos的字符之前插入串t */
{ int i;
char *temp;
if (pos<0 || pos>s->len || s->len==0) return(0);
temp=(char *)malloc(s->len t ->len);
if (temp==NULL) return(0);
for (i=0;i<pos;i ) temp[i]=s->ch[i];
for (i=0;i<t ->len;i ) temp[i pos]=t -> ch[i];
for (i=pos;i<s->len;i ) temp[i t.-> len]=s->ch[i];
s->len =t -> len;
free(s->ch);
s->ch=temp;
return(1);
}
(3)堆串删除函数
StrDelete(HString *s,int pos,int len)
/*在串s中删除从下标pos起len个字符 */
{ int i;
char *temp;
if (pos<0 || pos>(s->len - len)) return(0);
temp=(char *)malloc(s->len - len);
if (temp==NULL) return(0);
for (i=0;i<pos;i ) temp[i]=s->ch[i];
for (i=pos;i<s->len - len;i ) temp[i]=s->ch[i len];
s->len=s->len-len;
free(s->ch);
s->ch=temp;
return(1);
}
3.块链串
块链结构的定义
#define BLOCK_SIZE 4 /*每结点存放字符个数*/
typedef struct Block{
char ch[BLOCK_SIZE];
struct Block *next;
} Block;
typedef struct {
Block *head;
Block *tail;
int length;
} BLString;
【核心笔记】串的应用举例
1.文本编辑
文本编辑程序用于源程序的输入和修改,公文书信、报刊和书籍的编辑排版等。常用的文本编辑程序有Edit,WPS,Word等 。
为了编辑方便,可以用分页符和换行符将文本分为若干页,每页有若干行。我们把文本当作一个字符串,称为文本串,页是文本串的子串,行是页的子串。
我们采用堆存储结构来存储文本,同时设立页指针、行指针和字符指针,分别指向当前操作的页、行和字符,同时建立页表和行表存储每一页、每一行的起始位置和长度。
,