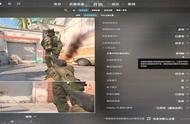
图5 常规CNN模型处理效果示范
处理之后编码artifacts被有效去除,画面比较干净平滑,但缺少细节和质感,例如:人像区域的头发/眉毛/胡子/皮肤颗粒感/嘴唇纹理等细节;地面草地纹理细节以及晚会节目视频中演员服装、道具细节丢失。
l 基于GAN的处理方案
为了解决常规CNN超分辨率模型缺乏细节、过平滑的问题,学术界在2017年提出了基于生成对抗网络(GAN)的超分辨率方案:超分辨率生成对抗网络(SRGAN)[5]。SRGAN在模型训练过程中,额外使用判别器对模型输出结果的纹理真实性进行鉴别,从而使得模型倾向输出具有一定细节纹理的结果。
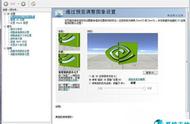
如下图所示,基于MSE的模型倾向输出平滑的结果,而基于GAN的模型倾向输出有一定纹理细节的结果。

图6 基于GAN的SR方案
来源:论文Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
基于GAN的超分辨率模型具有“无中生有”生成细节的能力,因此可以补充原始画面缺失的纹理细节,这对解决常规CNN模型过平滑问题有很大的帮助。在SRGAN模型之后,学术界有不少工作对这一技术方向进行不断的完善[6, 7]。
05
窄带高清GAN细节生成技术:
时域稳定的细节生成能力
然而,想要在实际业务场景中用好GAN生成技术,尤其是要在窄带高清全自动转码作业中应用该能力,技术实现层面还是有不少难点。
由于GAN的纹理细节是通过大量数据训练之后“脑补”出来的,那么“脑补”生成出来的细节纹理是否自然、与原始画面有没有违和感、相邻帧的生成结果是否具有一致性等,对该项技术能否在实际视频业务中成功应用至关重要。
具体来讲,要在窄带高清全自动转码作业中使用GAN生成能力,需要解决以下几个问题才能满足商用要求:
l 模型“脑补”生成的纹理自然,与原始画面没有违和感;
l 视频相邻帧的生成效果一致性高,连续播放无时域闪烁现象;
l 可应用于自动化处理流:模型对片源质量有良好的自适应能力,对不同画质损失程度不同的片源均有收益;
l 模型可适用于不同视频类型场景,例如影视剧,综艺,赛事,动画片等;
l 模型处理流程简单,处理耗时可预测、可控制(直播场景对处理效率有比较高的要求)。
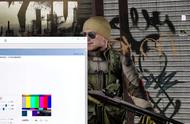
阿里云视频云音视频算法团队经过对GAN生成技术持续的钻研,积累了多项GAN模型优化技术,解决了上述GAN细节生成能力商用落地的难点问题,打造了一个可应用于全自动转码作业的GAN细节生成方案。该方案的核心优势是:时域稳定的细节生成能力。

图7 阿里云窄带高清GAN细节生成技术
具体来讲,在窄带高清GAN细节生成模型的训练过程中,我们使用了以下优化技术。
1.建立类型丰富、清晰度高、细节丰富的高画质视频库作为模型训练的高清样本,训练样本包含多样的纹理特征对GAN生成纹理的真实感有很大的帮助;
2.通过精细化建模不断优化训练数据的制备过程:基于对业务场景所面临的画质问题的深入洞察,贴合业务场景不断优化训练样本建模方法,不断探索以达到精细化建模;
3.探索积累有效的模型训练策略:
l 损失函数:训练损失函数配置调优,例如perceptual loss使用不同layer的feature,会影响生成纹理的颗粒度,不同loss的权重配比,也会影响纹理生成的效果;
l 训练方式:我们在模型训练过程使用了一种叫NoGAN的训练策略 [8]。在图像/视频上色GAN模型训练中,NoGAN训练策略被证实是一种非常有效的训练技巧:一方面可以提升模型的处理效果,另外一方面对模型生成效果的稳定性也有帮助。
4.模型对片源质量的自适应能力决定了其是否可应用于自动化处理作业。为了提高模型对片源质量的自适应能力,我们在训练输入样本质量的多样性和训练流程方面做了很多工作。最终我们训练得到的GAN模型具有良好的片源质量自适应能力:对中低质量视频源具有明显的细节生成增强能力、对高质量片源有适中的增强效果;
5.打造多场景处理能力:根据学术界的经验,处理目标先验信息越明确,GAN的生成能力越强。例如将GAN技术用于人脸或者文字修复,由于其处理对象单一(高维空间中的一个低维流形),可以得到非常惊艳的修复效果;
因此,为了提升GAN对不同场景的处理效果,我们采用了一种「1 N」的处理模式:「1」为打造一个适用于通用场景的GAN生成模型,具有比较温和的生成能力;「N」为多个垂直细分场景,针对垂直细分场景,在通用场景模型基础之上,对该场景特有的纹理细节进行比较激进的生成,例如:对于足球赛事场景,模型对赛场草地纹理有更强的生成效果;对于动画片场景,模型对线条有更强的生成能力;对于综艺节目,舞台表演场景,模型对人像特写细节有更强的生成能力。特别注意:如下所述,对于特定目标的生成效果提升,我们并没有采用特定目标单独处理的方案;
6.计算复杂度可控可预测的处理模式:直播场景对处理模型的运行效率有很高的要求。为了适配直播画质增强的需求,当下,我们采用了单个模型处理模式,即:对全幅图像,统一使用单个模型进行处理。即便要对某些特定目标的生成效果进行针对性提升,例如人像区域及足球场地草地纹理,我们并没有采用将目标抠出来,单独处理的方案。
因此,我们的模型推理时间是可预测的,与图像内容无关。经过模型蒸馏、轻量化,基于阿里云神龙HRT GPU推理框架,我们的GAN细节生成模型在单卡NVIDIA Tesla V100上,处理效率可达60fps@1920x1080。
GAN生成时域稳定性保障技术
为了保证GAN模型生成效果的帧间一致性,以避免帧间不连续带来视觉上的闪烁,我们通过与高校合作的方式,提出一种即插即用的帧间一致性增强模型 - Temporal Consistency Refinement Network (TCRNet)。TCRNet的工作流程主要包含以下三个步骤:
l 对单帧GAN处理结果进行后处理,达到增强GAN处理结果的帧间一致性的同时,增强部分细节,改善视觉效果;
l 使用偏移迭代修正模块(Iterative Residual Refinement of Offset Module,IRRO)结合可变形卷积,提高帧间运动补偿精度;
l 使用ConvLSTM模块,使模型能够融合更长距离的时序信息。并通过可变形卷积对传递的时序信息进行空间运动补偿,防止由于偏移造成的信息融合误差。