全文共1713字,预计学习时长3分钟

Pandas love eating data.
Pandas已经成为最受欢迎的数据科学库之一。它易于使用,内容丰富,且功能强大。
然而,无论使用什么库,大型数据集总是会带来意想不到的挑战,因此需要谨慎处理。
如果使用容量不足的随机存取存储器(RAM)来保存所有数据,就会产生硬件故障。企业公司存储的数据集大小在100GB到1000GB之间。
即使有幸拥有一台足以存储所有数据的机器,仅仅是将数据读入内存这一步就非常慢。
但Pandas库将再次帮助我们解决问题。本文将探讨的三种技术,可减少庞大数据集的内存占用和读取时间。这些技术曾用于处理超过100GB大小的数据集,可以将其压缩至内存为64GB甚至32GB的机器中。一起来看看吧!

来源:Pexels

数据分块
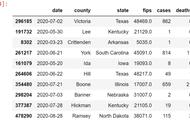
CSV格式是一种非常方便的数据存储方式,易于编写,且具有可读性。此外,pandas函数read_csv()在加载存储为CSV格式的数据方面表现良好。
但如果CSV文件太大,而内存又不够该怎么办?
Pandas可以轻而易举解决这个问题!相比于试图一次性处理所有数据,分块处理更加有效。通常,这些部分被称为“数据块”。
每一数据块只是数据集的一部分。它的大小可以根据内存容量任意变化。过程如下:
1. 读取数据块
2. 处理数据块
3. 保存结果
4. 重复步骤1-3直至得出所有结果
5. 整合所有结果
read_csv()函数中一个名为chunksize的方便变量可以执行上述所有步骤。Chunksize表示一次读取的CSV行数。行数多少取决于内存大小和每一行的大小。
如果数据能够轻松遵循高斯分布等模式,那么可以每次对一个块进行处理,并将其可视化。这种做法不会对其准确性产生很大影响。
如果是像泊松分布这类比较复杂的情况,则最好在处理前过滤每一个数据块,并将各部分整合在一起。大多数情况下,许多不相关的列或存在缺少值的行最终会被删除。对于每个数据块都可以执行此操作,使其变得更小,整合后对最终数据帧进行数据分析。
以下代码可执行所述步骤。