SqlSession 对于 insert、update、delete、select 的内部处理机制基本上大同小异。所以,接下来,我会以一次完整的 select 查询流程为例讲解 SqlSession 内部的工作机制。相信读者如果理解了 select 的处理流程,对于其他 CRUD 操作也能做到一通百通。
4.1 SqlSession 子组件
前面的内容已经介绍了:SqlSession 是 MyBatis 的顶层接口,它提供了所有执行语句,获取映射器和管理事务等方法。
实际上,SqlSession 是通过聚合多个子组件,让每个子组件负责各自功能的方式,实现了任务的下发。
在了解各个子组件工作机制前,先让我们简单认识一下 SqlSession 的核心子组件。
4.1.1 Executor
Executor 即执行器,它负责生成动态 SQL 以及管理缓存。

Executor 即执行器接口。
BaseExecutor
是 Executor 的抽象类,它采用了模板方法设计模式,内置了一些共性方法,而将定制化方法留给子类去实现。
SimpleExecutor
是最简单的执行器。它只会直接执行 SQL,不会做额外的事。
BatchExecutor
是批处理执行器。它的作用是通过批处理来优化性能。值得注意的是,批量更新操作,由于内部有缓存机制,使用完后需要调用 flushStatements 来清除缓存。
ReuseExecutor
是可重用的执行器。重用的对象是 Statement,也就是说,该执行器会缓存同一个 SQL 的 Statement,避免重复创建 Statement。其内部的实现是通过一个 HashMap 来维护 Statement 对象的。由于当前 Map 只在该 session 中有效,所以使用完后需要调用 flushStatements 来清除 Map。
CachingExecutor 是缓存执行器。它只在启用二级缓存时才会用到。
4.1.2 StatementHandler
StatementHandler 对象负责设置 Statement 对象中的查询参数、处理 JDBC 返回的 resultSet,将 resultSet 加工为 List 集合返回。
StatementHandler 的家族成员:

StatementHandler 是接口;
BaseStatementHandler
是实现 StatementHandler 的抽象类,内置一些共性方法;
SimpleStatementHandler
负责处理 Statement;
PreparedStatementHandler
负责处理 PreparedStatement;
CallableStatementHandler
负责处理 CallableStatement。
RoutingStatementHandler
负责代理 StatementHandler 具体子类,根据 Statement 类型,选择实例化 SimpleStatementHandler、
PreparedStatementHandler、
CallableStatementHandler。
4.1.3 ParameterHandler
ParameterHandler 负责将传入的 Java 对象转换 JDBC 类型对象,并为 PreparedStatement 的动态 SQL 填充数值。
ParameterHandler 只有一个具体实现类,即 DefaultParameterHandler。
4.1.4 ResultSetHandler
ResultSetHandler 负责两件事:
处理 Statement 执行后产生的结果集,生成结果列表
处理存储过程执行后的输出参数
ResultSetHandler 只有一个具体实现类,即 DefaultResultSetHandler。
4.1.5 TypeHandler
TypeHandler 负责将 Java 对象类型和 JDBC 类型进行相互转换。
4.2 SqlSession 和 Mapper
先来回忆一下 MyBatis 完整示例章节的 测试程序部分的代码。
MyBatisDemo.java 文件中的代码片段:
// 2. 创建一个 SqlSession 实例,进行数据库操作SqlSession sqlSession = factory.openSession;// 3. Mapper 映射并执行Long params = 1L;List<User> list = sqlSession.selectList("io.github.dunwu.spring.orm.mapper.UserMapper.selectByPrimaryKey", params);for (User user : list) { System.out.println("user name: " user.getName);}
示例代码中,给 sqlSession 对象的传递一个配置的 Sql 语句的 Statement Id 和参数,然后返回结果io.github.dunwu.spring.orm.mapper.
UserMapper.selectByPrimaryKey是配置在 UserMapper.xml 的 Statement ID,params 是 SQL 参数。
UserMapper.xml 文件中的代码片段:
<select id="selectByPrimaryKey" parameterType="java.lang.Long" resultMap="BaseResultMap"> select id, name, age, address, email from user where id = #{id,jdbcType=BIGINT} </select>
MyBatis 通过方法的全限定名,将 SqlSession 和 Mapper 相互映射起来。
4.3. SqlSession 和 Executor
org.apache.ibatis.session.defaults.DefaultSqlSession 中 selectList 方法的源码:
@Overridepublic <E> List<E> selectList(String statement) { return this.selectList(statement, );}@Overridepublic <E> List<E> selectList(String statement, Object parameter) { return this.selectList(statement, parameter, RowBounds.DEFAULT);}@Overridepublic <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) { try { // 1. 根据 Statement Id,在配置对象 Configuration 中查找和配置文件相对应的 MappedStatement MappedStatement ms = configuration.getMappedStatement(statement); // 2. 将 SQL 语句交由执行器 Executor 处理 return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " e, e); } finally { ErrorContext.instance.reset; }}
说明:
MyBatis 所有的配置信息都维持在 Configuration 对象之中。中维护了一个 Map<String, MappedStatement> 对象。其中,key 为 Mapper 方法的全限定名(对于本例而言,key 就是 io.github.dunwu.spring.orm.mapper.UserMapper.selectByPrimaryKey ),value 为 MappedStatement 对象。所以,传入 Statement Id 就可以从 Map 中找到对应的 MappedStatement。
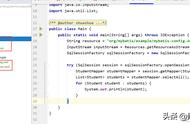
MappedStatement 维护了一个 Mapper 方法的元数据信息,数据组织可以参考下面 debug 截图:

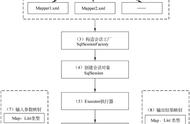
小结:通过 "SqlSession 和 Mapper" 以及 "SqlSession 和 Executor" 这两节,我们已经知道:SqlSession 的职能是:根据 Statement ID, 在 Configuration 中获取到对应的 MappedStatement 对象,然后调用 Executor 来执行具体的操作。
4.4. Executor 工作流程
继续上一节的流程,SqlSession 将 SQL 语句交由执行器 Executor 处理。那又做了哪些事呢?
(1)执行器查询入口
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { // 1. 根据传参,动态生成需要执行的 SQL 语句,用 BoundSql 对象表示 BoundSql boundSql = ms.getBoundSql(parameter); // 2. 根据传参,创建一个缓存Key CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql); return query(ms, parameter, rowBounds, resultHandler, key, boundSql); }
执行器查询入口主要做两件事:
生成动态 SQL:根据传参,动态生成需要执行的 SQL 语句,用 BoundSql 对象表示。
管理缓存:根据传参,创建一个缓存 Key。
(2)执行器查询第二入口
@SuppressWarnings("unchecked") @Override public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // 略 List<E> list; try { queryStack ; list = resultHandler == ? (List<E>) localCache.getObject(key) : ; // 3. 缓存中有值,则直接从缓存中取数据;否则,查询数据库 if (list != ) { handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } finally { queryStack--; } // 略 return list; }
实际查询方法主要的职能是判断缓存 key 是否能命中缓存:
命中,则将缓存中数据返回;
不命中,则查询数据库:
(3)查询数据库
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { List<E> list; localCache.putObject(key, EXECUTION_PLACEHOLDER); try { // 4. 执行查询,获取 List 结果,并将查询的结果更新本地缓存中 list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); } finally { localCache.removeObject(key); } localCache.putObject(key, list); if (ms.getStatementType == StatementType.CALLABLE) { localOutputParameterCache.putObject(key, parameter); } return list; }
queryFromDatabase 方法的职责是调用 doQuery,向数据库发起查询,并将返回的结果更新到本地缓存。
(4)实际查询方法。SimpleExecutor 类的 doQuery方法实现;
@Override public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = ; try { Configuration configuration = ms.getConfiguration; // 5. 根据既有的参数,创建StatementHandler对象来执行查询操作 StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); // 6. 创建java.Sql.Statement对象,传递给StatementHandler对象 stmt = prepareStatement(handler, ms.getStatementLog); // 7. 调用StatementHandler.query方法,返回List结果 return handler.query(stmt, resultHandler); } finally { closeStatement(stmt); } }
上述的 Executor.query方法几经转折,最后会创建一个 StatementHandler 对象,然后将必要的参数传递给 StatementHandler,使用 StatementHandler 来完成对数据库的查询,最终返回 List 结果集。从上面的代码中我们可以看出,Executor 的功能和作用是:
根据传递的参数,完成 SQL 语句的动态解析,生成 BoundSql 对象,供 StatementHandler 使用;
为查询创建缓存,以提高性能
创建 JDBC 的 Statement 连接对象,传递给 StatementHandler 对象,返回 List 查询结果。
prepareStatement 方法的实现:
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { Statement stmt; Connection connection = getConnection(statementLog); stmt = handler.prepare(connection, transaction.getTimeout); //对创建的Statement对象设置参数,即设置SQL 语句中 ? 设置为指定的参数 handler.parameterize(stmt); return stmt; }
对于 JDBC 的 PreparedStatement 类型的对象,创建的过程中,我们使用的是 SQL 语句字符串会包含若干个占位符,我们其后再对占位符进行设值。
4.5. StatementHandler 工作流程
StatementHandler 有一个子类 RoutingStatementHandler,它负责代理其他 StatementHandler 子类的工作。
它会根据配置的 Statement 类型,选择实例化相应的 StatementHandler,然后由其代理对象完成工作。
【源码】RoutingStatementHandler
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { switch (ms.getStatementType) { case STATEMENT: delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; case PREPARED: delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; case CALLABLE: delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; default: throw new ExecutorException("Unknown statement type: " ms.getStatementType); }}
【源码】RoutingStatementHandler 的
parameterize 方法源码
【源码】PreparedStatementHandler 的
parameterize 方法源码
StatementHandler使用ParameterHandler对象来完成对Statement 的赋值。
@Overridepublic void parameterize(Statement statement) throws SQLException { // 使用 ParameterHandler 对象来完成对 Statement 的设值 parameterHandler.setParameters((PreparedStatement) statement);}
【源码】StatementHandler 的 query 方法源码
StatementHandler 使用 ResultSetHandler 对象来完成对 ResultSet 的处理。
@Overridepublic <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException { PreparedStatement ps = (PreparedStatement) statement; ps.execute; // 使用ResultHandler来处理ResultSet return resultSetHandler.handleResultSets(ps);}
4.6. ParameterHandler 工作流程
【源码】DefaultParameterHandler 的
setParameters 方法
@Override public void setParameters(PreparedStatement ps) { // parameterMappings 是对占位符 #{} 对应参数的封装 List<ParameterMapping> parameterMappings = boundSql.getParameterMappings; if (parameterMappings != ) { for (int i = 0; i < parameterMappings.size; i ) { ParameterMapping parameterMapping = parameterMappings.get(i); // 不处理存储过程中的参数 if (parameterMapping.getMode != ParameterMode.OUT) { Object value; String propertyName = parameterMapping.getProperty; if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params // 获取对应的实际数值 value = boundSql.getAdditionalParameter(propertyName); } else if (parameterObject == ) { value = ; } else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass)) { value = parameterObject; } else { // 获取对象中相应的属性或查找 Map 对象中的值 MetaObject metaObject = configuration.newMetaObject(parameterObject); value = metaObject.getValue(propertyName); } TypeHandler typeHandler = parameterMapping.getTypeHandler; JdbcType jdbcType = parameterMapping.getJdbcType; if (value == && jdbcType == ) { jdbcType = configuration.getJdbcTypeFor; } try { // 通过 TypeHandler 将 Java 对象参数转为 JDBC 类型的参数 // 然后,将数值动态绑定到 PreparedStaement 中 typeHandler.setParameter(ps, i 1, value, jdbcType); } catch (TypeException | SQLException e) { throw new TypeException("Could not set parameters for mapping: " parameterMapping ". Cause: " e, e); } } } } }
4.7. ResultSetHandler 工作流程
ResultSetHandler 的实现可以概括为:将 Statement 执行后的结果集,按照 Mapper 文件中配置的 ResultType 或 ResultMap 来转换成对应的 JavaBean 对象,最后将结果返回。
【源码】DefaultResultSetHandler 的 handleResultSets 方法。handleResultSets 方法是 DefaultResultSetHandler 的最关键方法。其实现如下:
@Overridepublic List<Object> handleResultSets(Statement stmt) throws SQLException { ErrorContext.instance.activity("handling results").object(mappedStatement.getId); final List<Object> multipleResults = new ArrayList<>; int resultSetCount = 0; // 第一个结果集 ResultSetWrapper rsw = getFirstResultSet(stmt); List<ResultMap> resultMaps = mappedStatement.getResultMaps; // 判断结果集的数量 int resultMapCount = resultMaps.size; validateResultMapsCount(rsw, resultMapCount); // 遍历处理结果集 while (rsw != && resultMapCount > resultSetCount) { ResultMap resultMap = resultMaps.get(resultSetCount); handleResultSet(rsw, resultMap, multipleResults, ); rsw = getNextResultSet(stmt); cleanUpAfterHandlingResultSet; resultSetCount ; } String resultSets = mappedStatement.getResultSets; if (resultSets != ) { while (rsw != && resultSetCount < resultSets.length) { ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]); if (parentMapping != ) { String nestedResultMapId = parentMapping.getNestedResultMapId; ResultMap resultMap = configuration.getResultMap(nestedResultMapId); handleResultSet(rsw, resultMap, , parentMapping); } rsw = getNextResultSet(stmt); cleanUpAfterHandlingResultSet; resultSetCount ; } } return collapseSingleResultList(multipleResults);}
五、参考资料
官方
MyBatis Github
MyBatis 官网
MyBatis Generator
Spring 集成
Spring Boot 集成
扩展插件
MyBatis-plus - CRUD 扩展插件、代码生成器、分页器等多功能
Mapper - CRUD 扩展插件
MyBatis-PageHelper - MyBatis 通用分页插件
文章
《深入理解 MyBatis 原理》
《MyBatis 源码中文注释》
《MyBatis 中强大的 resultMap》
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
高可用架构
改变互联网的构建方式