图5. NBA球员统计数据的散布图示例
3. 数据预处理数据预处理(又称数据清理、数据整理或数据处理)是指对数据进行各种检查和审查的过程,以纠正缺失值、拼写错误、使数值正常化/标准化以使其具有可比性、转换数据(如对数转换)等问题。
"Garbage in, Garbage out."
正如上面的引言所说,数据的质量将对生成模型的质量产生很大的影响。因此,为了达到最高的模型质量,应该在数据预处理阶段花费大量精力。一般来说,数据预处理可以轻松地占到数据科学项目所花费时间的80%,而实际的模型建立阶段和后续的模型分析仅占到剩余的20%。
4. 数据分割4.1 训练--测试集分割
在机器学习模型的开发过程中,希望训练好的模型能在新的、未见过的数据上表现良好。为了模拟新的、未见过的数据,对可用数据进行数据分割,从而将其分割成2部分(有时称为训练—测试分割)。特别是,第一部分是较大的数据子集,用作训练集(如占原始数据的80%),第二部分通常是较小的子集,用作测试集(其余20%的数据)。需要注意的是,这种数据拆分只进行一次。
接下来,利用训练集建立预测模型,然后将这种训练好的模型应用于测试集(即作为新的、未见过的数据)上进行预测。根据模型在测试集上的表现来选择最佳模型,为了获得最佳模型,还可以进行超参数优化。

图6. 训练—测试集分割示意图
4.2 训练--验证--测试集分割
另一种常见的数据分割方法是将数据分割成3部分。(1) 训练集,(2) 验证集和(3) 测试集。与上面解释的类似,训练集用于建立预测模型,同时对验证集进行评估,据此进行预测,可以进行模型调优(如超参数优化),并根据验证集的结果选择性能最好的模型。正如我们所看到的,类似于上面对测试集进行的操作,这里我们在验证集上做同样的操作。请注意,测试集不参与任何模型的建立和准备。因此,测试集可以真正充当新的、未知的数据。Google的《机器学习速成班》对这个话题进行了更深入的处理。

图7. 训练—验证—测试集分割示意图
4.3 交叉验证
为了最经济地利用现有数据,通常使用N倍交叉验证(CV),将数据集分割成N个折(即通常使用5倍或10倍CV)。在这样的N倍CV中,其中一个折被留作测试数据,而其余的折则被用作建立模型的训练数据。
例如,在5倍CV中,有1个折被省略,作为测试数据,而剩下的4个被集中起来,作为建立模型的训练数据。然后,将训练好的模型应用于上述遗漏的折(即测试数据)。这个过程反复进行,直到所有的折都有机会被留出作为测试数据。因此,我们将建立5个模型(即5个折中的每个折都被留出作为测试集),其中5个模型中的每个模型都包含相关的性能指标(我们将在接下来的部分讨论)。最后,度量(指标)值是基于5个模型计算出的平均性能。

图8. 交叉验证示意图
在N等于数据样本数的情况下,我们称这种留一的交叉验证。在这种类型的CV中,每个数据样本代表一个折。例如,如果N等于30,那么就有30个折(每个折有1个样本)。在任何其他N折CV中,1个折点被留出作为测试集,而剩下的29个折点被用来建立模型。接下来,将建立的模型应用于对留出的折进行预测。与之前一样,这个过程反复进行,共30次;计算30个模型的平均性能,并将其作为CV性能指标。
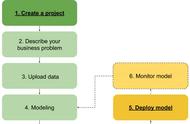
5. 模型建立现在,有趣的部分来了,我们终于可以使用精心准备的数据来建立模型了。根据目标变量(通常称为Y变量)的数据类型(定性或定量),我们要建立一个分类(如果Y是定性的)或回归(如果Y是定量的)模型。
5.1 学习算法
机器学习算法可以大致分为以下三种类型之一:
- 监督学习:是一种机器学习任务,建立输入X和输出Y变量之间的数学(映射)关系。这样的X、Y对构成了用于建立模型的标签数据,以便学习如何从输入中预测输出。
- 无监督学习:是一种只利用输入X变量的机器学习任务。这种 X 变量是未标记的数据,学习算法在建模时使用的是数据的固有结构。
- 强化学习:是一种决定下一步行动方案的机器学习任务,它通过试错学习来实现这一目标,努力使回报最大化。
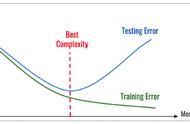
5.2 参数调优
超参数本质上是机器学习算法的参数,直接影响学习过程和预测性能。由于没有“一刀切 ”的超参数设置,可以普遍适用于所有数据集,因此需要进行超参数优化(也称为超参数调整或模型调整)。
我们以随机森林为例。在使用randomForest R包时,通常会对两个常见的超参数进行优化,其中包括mtry和ntree参数(这对应于scikit-learnPython库中RandomForestClassifier()和RandomForestRegressor()函数中的nestimators和maxfeatures)。mtry(maxfeatures)代表在每次分裂时作为候选变量随机采样的变量数量,而ntree(nestimators)代表要生长的树的数量。
另一种流行的机器学习算法是支持向量机。需要优化的超参数是径向基函数(RBF)内核的C参数和gamma参数(即线性内核只有C参数;多项式内核的C和指数)。C参数是一个限制过拟合的惩罚项,而gamma参数则控制RBF核的宽度。如上所述,调优通常是为了得出超参数的最佳值集,尽管如此,也有一些研究旨在为C参数和gamma参数找到良好的起始值(Alvarsson等人,2014)。
地址:
https://pubs.acs.org/doi/10.1021/ci500344v
5.3 特征选择
顾名思义,特征选择从字面上看就是从最初的大量特征中选择一个特征子集的过程。除了实现高精度的模型外,机器学习模型构建最重要的一个方面是获得可操作的见解,为了实现这一目标,能够从大量的特征中选择出重要的特征子集非常重要。
特征选择的任务本身就可以构成一个全新的研究领域,在这个领域中,大量的努力都是为了设计新颖的算法和方法。从众多可用的特征选择算法中,一些经典的方法是基于模拟退火和遗传算法。除此之外,还有大量基于进化算法(如粒子群优化、蚁群优化等)和随机方法(如蒙特卡洛)的方法。
我们自己的研究小组也在对醛糖还原酶抑制剂的定量结构—活性关系建模的研究中,探索了利用蒙特卡洛模拟进行特征选择的方法(Nantasenamat等,2014)。
地址:
https://doi.org/10.1016/j.ejmech.2014.02.043
在《遗传算法搜索空间拼接粒子群优化作为通用优化器》的工作中,我们还设计了一种基于结合两种流行的进化算法即遗传算法和粒子群算法的新型特征选择方法(Li等,2013)。
地址:
https://doi.org/10.1016/j.chemolab.2013.08.009