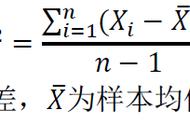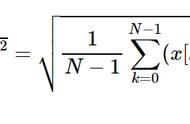当我们对数据总体进行统计时,由于每一个数据都被使用到,所以计算得到的标准差和方差是能够准确体现整个数据集特征的。而当从总体中提取出某个样本时,该样本当中的数据在一定程度上会集中在某个范围之中,由此计算出来的标准差和方差不能准确体现出数据总体的情况,通常来说得到的结果会比总体的要小。
举一个例子,如果一个数据集满足高斯分布(Normal Distribution),那当我们提取样本的时候,数据基本上会集中在中间的部分,而边缘值的数目可能会比较少,所以最后得到的样本方差和样本标准差会比总体要小。为了修正这个偏差,在计算样本的方差和标准差时,我们将使用 n-1 代替 n。这样处理后最直接的结果是,公式中的分母变小,得到的结果将会变大,能够更加准确地通过该样本预测总体的情况。
对于一个随机变量X进行n次抽样,获得样本

,那么样本均值为

有偏样本方差为:

无偏样本方差为: