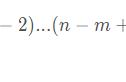相信大家已经对 Pandas 或 SQL 等其他关系数据库非常熟悉了。我们习惯于将行中的用户视为列。但现实世界的表现真的如此吗?
在互联世界中,用户不能被视为独立实体。他们之间具有一定的关系,在构建机器学习模型时,有时也希望包含这样的关系。
在关系型数据库中,我们无法在不同的行(用户)之间使用这种关系,但在图形数据库中,这样做是相当简单的。在这篇Python学习教程中将为大家介绍一些重要的图算法,以及Python 的代码实现。
1、连通分量
具有三个连通分量的图
将上图中的连通分量算法近似看作一种硬聚类算法,该算法旨在寻找相关数据的簇类。举一个具体的例子:假设拥有连接世界上任意城市的路网数据,我们需要找出世界上所有的大陆,以及它们所包含的城市。我们该如何实现这一目标呢?
基于BFS / DFS的连通分量算法能够达成这一目的,接下来,我们将用 Networkx 实现这一算法。
代码
使用 Python 中的 Networkx 模块来创建和分析图数据库。如下面的示意图所示,图中包含了各个城市和它们之间的距离信息。

示意图
首先创建边的列表,列表中每个元素包含两个城市的名称,以及它们之间的距离。
edgelist = [['Mannheim', 'Frankfurt', 85], ['Mannheim', 'Karlsruhe', 80], ['Erfurt', 'Wurzburg', 186], ['Munchen', 'Numberg', 167], ['Munchen', 'Augsburg', 84], ['Munchen', 'Kassel', 502], ['Numberg', 'Stuttgart', 183], ['Numberg', 'Wurzburg', 103], ['Numberg', 'Munchen', 167], ['Stuttgart', 'Numberg', 183], ['Augsburg', 'Munchen', 84], ['Augsburg', 'Karlsruhe', 250], ['Kassel', 'Munchen', 502], ['Kassel', 'Frankfurt', 173], ['Frankfurt', 'Mannheim', 85], ['Frankfurt', 'Wurzburg', 217], ['Frankfurt', 'Kassel', 173], ['Wurzburg', 'Numberg', 103], ['Wurzburg', 'Erfurt', 186], ['Wurzburg', 'Frankfurt', 217], ['Karlsruhe', 'Mannheim', 80], ['Karlsruhe', 'Augsburg', 250],["Mumbai", "Delhi",400],["Delhi", "Kolkata",500],["Kolkata", "Bangalore",600],["TX", "NY",1200],["ALB", "NY",800]]
然后,使用 Networkx 创建图:
g = nx.Graph() for edge in edgelist: g.add_edge(edge[0],edge[1], weight = edge[2])
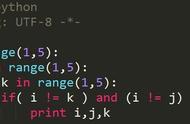
现在,我们想从这张图中找出不同的大陆及其包含的城市。我们可以使用使用连通分量算法来执行此操作:
for i, x in enumerate(nx.connected_components(g)): print("cc" str(i) ":",x) cc0: {'Frankfurt', 'Kassel', 'Munchen', 'Numberg', 'Erfurt', 'Stuttgart', 'Karlsruhe', 'Wurzburg', 'Mannheim', 'Augsburg'} cc1: {'Kolkata', 'Bangalore', 'Mumbai', 'Delhi'} cc2: {'ALB', 'NY', 'TX'}
从结果中可以看出,只需使用边缘和顶点,我们就能在数据中找到不同的连通分量。 该算法可以在不同的数据上运行,以满足前文提到的两种其他运用。
应用:
零售:很多客户使用大量账户,可以利用连通分量算法寻找数据集中的不同簇类。假设使用相同信用卡的客户 ID 存在连边(edges),或者将该条件替换为相同的住址,或者相同的电话等。一旦我们有了这些连接的边,就可以使用连通分量算法来对客户 ID 进行聚类,并对每个簇类分配一个家庭 ID。然后,通过使用这些家庭 ID,我们可以根据家庭需求提供个性化建议。此外,通过创建基于家庭的分组功能,我们还能够提高分类算法的性能。
财务:我们可以利用这些家庭 ID 来识别金融欺诈。如果某个账户曾经有过欺诈行为,那么它的关联帐户很可能发生欺诈行为。
2、最短路径继续第一节中的例子,我们拥有了德国的城市群及其相互距离的图表。为了计算从法兰克福前往慕尼黑的最短路径,我们需要用到 Dijkstra 算法。Dijkstra 是这样描述他的算法的:
从鹿特丹到格罗宁根的最短途径是什么?或者换句话说:从特定城市到特定城市的最短路径是什么?这便是最短路径算法,而我只用了二十分钟就完成了该算法的设计。 一天早上,我和未婚妻在阿姆斯特丹购物,我们逛累了,便在咖啡馆的露台上喝了一杯咖啡。而我,就想着我能够做到这一点,于是我就设计了这个最短路径算法。正如我所说,这是一个二十分钟的发明。事实上,它发表于1959年,也就是三年后。它之所以如此美妙,其中一个原因在于我没有用铅笔和纸张就设计了它。后来我才知道,没有铅笔和纸的设计的一个优点就是,你几乎被迫避免所有可避免的复杂性。最终,这个算法让我感到非常惊讶,而且也成为了我名声的基石之一。——Edsger Dijkstra于2001年接受ACM通讯公司 Philip L. Frana 的采访时的回答
代码
print(nx.shortest_path(g, 'Stuttgart','Frankfurt',weight='weight')) print(nx.shortest_path_length(g, 'Stuttgart','Frankfurt',weight='weight')) ['Stuttgart', 'Numberg', 'Wurzburg', 'Frankfurt'] 503
使用以下命令可以找到所有对之间的最短路径:
for x in nx.all_pairs_dijkstra_path(g,weight='weight'): print(x) ('Mannheim', {'Mannheim': ['Mannheim'], 'Frankfurt': ['Mannheim', 'Frankfurt'], 'Karlsruhe': ['Mannheim', 'Karlsruhe'], 'Augsburg': ['Mannheim', 'Karlsruhe', 'Augsburg'], 'Kassel': ['Mannheim', 'Frankfurt', 'Kassel'], 'Wurzburg': ['Mannheim', 'Frankfurt', 'Wurzburg'], 'Munchen': ['Mannheim', 'Karlsruhe', 'Augsburg', 'Munchen'], 'Erfurt': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Erfurt'], 'Numberg': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Numberg'], 'Stuttgart': ['Mannheim', 'Frankfurt', 'Wurzburg', 'Numberg', 'Stuttgart']}) ('Frankfurt', {'Frankfurt': ['Frankfurt'], 'Mannheim': ['Frankfurt', 'Mannheim'], 'Kassel': ['Frankfurt', 'Kassel'], 'Wurzburg': ['Frankfurt', 'Wurzburg'], 'Karlsruhe': ['Frankfurt', 'Mannheim', 'Karlsruhe'], 'Augsburg': ['Frankfurt', 'Mannheim', 'Karlsruhe', 'Augsburg'], 'Munchen': ['Frankfurt', 'Wurzburg', 'Numberg', 'Munchen'], 'Erfurt': ['Frankfurt', 'Wurzburg', 'Erfurt'], 'Numberg': ['Frankfurt', 'Wurzburg', 'Numberg'], 'Stuttgart': ['Frankfurt', 'Wurzburg', 'Numberg', 'Stuttgart']}) ....
应用
- Dijkstra 算法的变体在 Google 地图中广泛使用,用于计算最短的路线。
- 想象身处在沃尔玛商店,我们知道了各个过道之间的距离,我们希望为从过道 A 到过道 D 的客户提供最短路径。

- 如下图所示,当我们知道了领英中用户的一级连接、二级连接时,如何得知幕后的信息呢?Dijkstra 算法可以帮到我们。