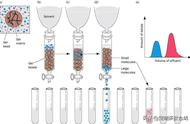
我们搭建了基于知识图谱的异构召回模型。该方法以知识图谱给出的“先验”关系信息,将文章feature与用户feature做关联,构建出一个同时包括用户特征又包括文章的特征的异构网络,通过图谱异构网络的表示学习,得到异构节点的向量(user profile feature与doc feature)。
已经有相关理论支持,可以得到特征之间的独立性与向量的加和性,从而实现在特征匮乏情况下,不会过渡依赖单一用户需求或内容画像特征进行召回,对合并后的向量相关性计算召回与该用户最相关文章。
2)试探(兴趣试探/内容试探)
解决两类问题,拓宽用户的兴趣面,减少发现优质内容的周期。试探能力需要打通整个推荐系统的绿色pass通路,允许内容或兴趣召回可以全链路走特殊通路:包括:数据通路,模型通路,定制召回/排序/混排模型等能力。

我们召回通过设计两类试探策略,解决上述问题:
兴趣试探:我们系统中通过:跨域用户兴趣试探,中长尾闭集合兴趣试探,全集合兴趣试探模型三类策略就行兴趣试探。并建设了一套以用户需求的试探成功率,试探标签的有点率,点击率衡量试探效果的实验体系,可以闭环的验证链路效果。

内容试探:我们设计了:内容质量识别(离线),运营系统(旁路),流量预估(在线),内容投放目标性识别(在线)来投放与优化投放效果,通过全链路的对内容标签修订,试探投放,日志模型定制化,迁移学习,上线后以ABTest中以新内容系统获取曝光后的试探内容点击率,试探成功率,试探多样性衡量闭环效果。

4. 深度模型召回
下文对这部分工作进行概要介绍,按类别我们将模型召回分为四类:
五、深度模型召回召回是处于推荐业务的底层位置,首先,处理数据规模相比上层排序要大几个数量级,其次,要求准确的同时,兼顾多种业务和用户体验目标,例如:多样性,社交,时长,负反馈,分享等等。在诸多限制下,模型召回系统会着重解决几个问题:
- 候选数据规模大;对模型性能要求高;
- user-item 交叉类特征算法,由于召回的检索逻辑限制,这类算法支持不友好;
- 底层数据种类繁多,模型需要具备很强的自适应能力;
- 解决:多样性与精确性的两难选择;
- 模型实时性问题增量模型;
- 用户/内容冷启的召回问题;
- 横向业务演化阶段,模型如何快速孵化新业务,即迁移能力。