文章每周持续更新,原创不易,「三连」让更多人看到是对我最大的肯定。可以微信搜索公众号「 后端技术学堂 」第一时间阅读(一般比博客早更新一到两篇)

很多同学应该都知道什么是哈希函数,在后端面试和开发中会遇到「一致性哈希」,那么什么是一致性哈希呢?名字听起来很厉害的样子,其实原理并不复杂,这篇文章带你彻底搞懂一致性哈希!
进入主题前,先来一场紧张刺激的模拟面试吧。

模拟面试表情.png
面试官:看你简历上写参与了一个大型项目,用到了分布式缓存集群,那你说说你们是怎么做缓存负载均衡?
萌新 :这个我知道,我们用的是轮询方式,第一个key 给第一个存储节点,第二个 key 给第二个,以此类推。
面试官:还有其他解决方案吗?
萌新:可以用哈希函数,把请求打散随机分配到缓存集群内机器。
面试官:考虑过这种哈希方式负载均衡的扩展性和容错性吗?
萌新:...
面试官:回去等通知吧。
以上如有雷同,算你抄我的。
什么是哈希数据结构中我们学习过哈希表也称为散列表,我们来回顾下散列表的定义。
散列表,是根据键直接访问在指定储存位置数据的数据结构。通过计算一个关于键的函数也称为哈希函数,将所需查询的数据映射到表中一个位置来访问记录,加快查找速度。这个映射函数称做「散列函数」,存放记录的数组称做散列表。
散列函数能使对一个数据序列的访问过程更加迅速有效,是一种空间换时间的算法,通过散列函数数据元素将被更快定位。
下图示意了字符串经过哈希函数映射到哈希表的过程。没错,输入字符串是用脸滚键盘打出来的:)

哈希示意图.png
常见的哈希算法有MD5、CRC 、MurmurHash 等算法。
MD5算法MD5消息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),MD5算法将数据(如一段文字)运算变为另一固定长度值,是散列算法的基础原理。由美国密码学家 Ronald Linn Rivest设计,于1992年公开并在 RFC 1321 中被加以规范。
CRC算法循环冗余校验(Cyclic Redundancy Check)是一种根据网络数据包或电脑文件等数据,产生简短固定位数校验码的一种散列函数,由 W. Wesley Peterson 于1961年发表。生成的数字在传输或者存储之前计算出来并且附加到数据后面,然后接收方进行检验确定数据是否发生变化。由于本函数易于用二进制的电脑硬件使用、容易进行数学分析并且尤其善于检测传输通道干扰引起的错误,因此获得广泛应用。
MurmurHashMurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作。由 Austin Appleby 在2008年发明,并出现了多个变种,与其它流行的哈希函数相比,对于规律性较强的键,MurmurHash的随机分布特征表现更良好。
这个算法已经被很多开源项目使用,比如libstdc (4.6版)、Perl、nginx (不早于1.0.1版)、Rubinius、 libmemcached、maatkit、Hadoop等。
常见散列方法- 直接定址法:取关键字或关键字的某个线性函数值为散列地址,这个线性函数的定义多种多样,没有标准。
- 数字分析法:假设关键字是以r为基的数,并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
- 平方取中法:取关键字平方后的中间几位为哈希地址。通常在选定哈希函数时不一定能知道关键字的全部情况,取其中的哪几位也不一定合适,而一个数平方后的中间几位数和数的每一位都相关,由此使随机分布的关键字得到的哈希地址也是随机的,取的位数由表长决定。
- 折叠法:将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。
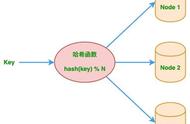
- 取模法:取关键字被某个不大于散列表表长 m 的数 p 除后所得的余数为散列地址。即 hash(key) = key % p(p<= M),不仅可以对关键字直接取模,也可在折叠法、平方取中法等运算之后取模。对 p 的选择很重要,一般取素数或 m,若 p 选择不好,容易产生冲突。
在分布式集群缓存的负载均衡实现中,比如 memcached 缓存集群,需要把缓存数据的 key 利用哈希函数散列,这样缓存数据能够均匀分布到各个分布式存储节点上,要实现这样的负载均衡一般可以用哈希算法来实现。下图演示了这一分布式存储过程: