作者:小傅哥
博客:https://bugstack.cn
一、前言沉淀、分享、成长,让自己和他人都能有所收获!
哈希表的历史
哈希散列的想法在不同的地方独立出现。1953 年 1 月,汉斯·彼得·卢恩 ( Hans Peter Luhn ) 编写了一份IBM内部备忘录,其中使用了散列和链接。开放寻址后来由 AD Linh 在 Luhn 的论文上提出。大约在同一时间,IBM Research的Gene Amdahl、Elaine M. McGraw、Nathaniel Rochester和Arthur Samuel为IBM 701汇编器实现了散列。 线性探测的开放寻址归功于 Amdahl,尽管Ershov独立地有相同的想法。“开放寻址”一词是由W. Wesley Peterson在他的文章中创造的,该文章讨论了大文件中的搜索问题。
二、哈希数据结构哈希表的存在是为了解决能通过O(1)时间复杂度直接索引到指定元素。
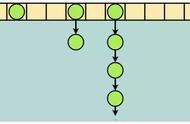
这是什么意思呢?通过我们使用数组存放元素,都是按照顺序存放的,当需要获取某个元素的时候,则需要对数组进行遍历,获取到指定的值。如图所示;

而这样通过循环遍历比对获取指定元素的操作,时间复杂度是O(n),也就是说如果你的业务逻辑实现中存在这样的代码是非常拉胯的。那怎么办呢?这就引入了哈希散列表的设计。
在计算机科学中,一个哈希表(hash table、hash map)是一种实现关联数组的抽象数据结构,该结构将键通过哈希计算映射到值。
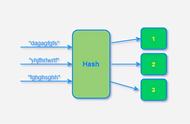
也就是说我们通过对一个 Key 值计算它的哈希并与长度为2的n次幂的数组减一做与运算,计算出槽位对应的索引,将数据存放到索引下。那么这样就解决了当获取指定数据时,只需要根据存放时计算索引ID的方式再计算一次,就可以把槽位上对应的数据获取处理,以此达到时间复杂度为O(1)的情况。如图所示;

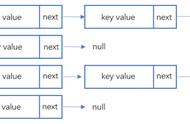
哈希散列虽然解决了获取元素的时间复杂度问题,但大多数时候这只是理想情况。因为随着元素的增多,很可能发生哈希冲突,或者哈希值波动不大导致索引计算相同,也就是一个索引位置出现多个元素情况。如图所示;

当李二狗、拎瓢冲都有槽位的下标索引03的 叮裆猫 发生冲突时,情况就变得糟糕了,因为这样就不能满足O(1)时间复杂度获取元素的诉求了。
那么此时就出现了一系列解决方案,包括;HashMap 中的拉链寻址 红黑树、扰动函数、负载因子、ThreadLocal 的开放寻址、合并散列、杜鹃散列、跳房子哈希、罗宾汉哈希等各类数据结构设计。让元素在发生哈希冲突时,也可以存放到新的槽位,并尽可能保证索引的时间复杂度小于O(n)
三、实现哈希散列哈希散列是一个非常常见的数据结构,无论是我们使用的 HashMap、ThreaLocal 还是你在刷题中位了提升索引效率,都会用到哈希散列。
只要哈希桶的长度由负载因子控制的合理,每次查找元素的平均时间复杂度与桶中存储的元素数量无关。另外许多哈希表设计还允许对键值对的任意插入和删除,每次操作的摊销固定平均成本。
好,那么介绍了这么多,小傅哥带着大家做几个关于哈希散列的数据结构,通过实践来了解会更加容易搞懂。
- 源码地址:https://github.com/fuzhengwei/java-algorithms- Java 算法与数据结构
- 本章源码:https://github.com/fuzhengwei/java-algorithms/tree/main/data-structures/src/main/java/hash_table
- 扩展资料:《Java 面经手册》 - 本章涉及到的拉链寻址、开放寻址在 Java API 中的 HashMap、ThreadLocal 有完整实现,同时涉及了扰动函数、负载因子、斐波那契散列,可以扩展学习。
说明:通过模拟简单 HashMap 实现,去掉拉链寻址等设计,验证元素哈新索引位置碰撞。
public class HashMap01<K, V> implements Map<K, V> {
private final Object[] tab = new Object[8];
@Override
public void put(K key, V value) {
int idx = key.hashCode() & (tab.length - 1);
tab[idx] = value;
}
@Override
public V get(K key) {
int idx = key.hashCode() & (tab.length - 1);
return (V) tab[idx];
}
}