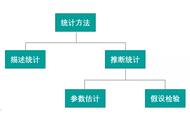
其中μ是期望值,σ是标准差(方差的平方根)。高斯分布的函数图像如下,变量在平均值附近左右一个标准差内的概率是68.2%。

在深度学习中,我们需要调节神经网络的参数以防止过度拟合。这时候会用到指数分布:

λ值越大,变量x的分布越集中。

概率不仅仅是掌握机器学习必需的基础知识,它也有一些直接的应用。
在前文中我们提到过,指数分布可以帮助调节神经网络的参数,防止过拟合。这一点很重要,因为过拟合会导致神经网络的性能不佳。
在Kaggle的一项预测客户交易的任务中,作者Nimish用概率论的方法找到了内部规律。
Nimish绘制了200个变量对结果分布的影响: