为帮助学习pandas,特意从和鲸社区中提炼出120道经典数据处理常见操作例题,从基础入门到进阶来更快速、更专业的角度理解pandas。主要包括:
- Pandas基础
- Pandas进阶
- 金融数据处理
- NumPy科学计算
- 一些补充
(https://www.heywhale.com/mw/project/5ef96ce863975d002c95fd8a/content)
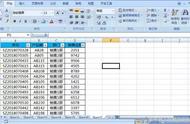
原始数据打印:
数据存储在Excel中,因为利用pd.read_excel()函数,读取数据
import pandas as pd
import numpy as np
data=pd.read_excel('Excel_test.xlsx')
data.head()

需求确认:
现需要根据salary_列 新增一列categories,依据值 0~5000:低,5000~20000:中,20000~50000:高
代码实现:
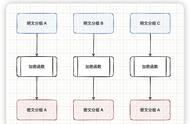
方法一:新建函数salary_categories,并根据if语句判断值大小,并赋值给低中高,然后利用apply()方法,遍历数据。
def salary_categories(x):
if x>20000 and x<=50000:
result='高'
elif x>5000 and x<=20000:
result='中'
else:
result='低'
return result
data['categories']=data['salary_'].apply(salary_categories)
data

方法二:利用cut()方法,将salary_列中数据离散化,形成需要的数据
bins = [0,5000, 20000, 50000]
group_names = ['低', '中', '高']
data['categories_2'] = pd.cut(data['salary_'], bins, labels=group_names)
data

总结:此案例使用两种方法实现新增列。分别是函数、cut()方法。
函数:函数中使用if语句对数值数据进行判断,并分别归为三类,最后利用apply()方法调用函数,实现了新增列。
cut()方法就简单的多了,设置分组区间,并对区间分类划分,同样实现了新增列。
通过对比可得,cut()方法简单明了,容易理解,推荐使用。