文 / 交通银行软件开发中心 俞书浩

手机银行APP已成为银行客户申购理财、基金、保险等产品的主流销售渠道,因此需要更快速地了解客户行为,以此做营销推荐模型,给出及时的产品推荐。例如客户某天上午使用过APP,当下午再次打开APP时,推荐页面的产品已经更新。但由于手机银行APP迭代更新速度很快,用户操作路径经常变化,加上各类新产品层出不穷(如消费贷、ETC等),经济环境的变化(如疫情),都会导致客群分布和行为特征总在变化中。传统的机器学习建模方法针对这种瞬息万变的情况无法适应,很可能辛辛苦苦做好的模型,一两个星期就不准确了。本文提出一种“进化环机器学习法”来改进营销推荐建模的流程,以应对快速变化的世界。
传统机器学习方法的建模流程传统机器学习方法的建模流程,从需求分析、数据准备到模型投产,最终失效共有8个环节。
以营销推荐模型为例,从需求分析开始,首先指定建模的目标,如提高理财产品的点击率;接着是数据准备,收集客户的资产交易签约以及APP行为等各种数据;然后清洗数据,发现异常数据,提高数据质量;并衍生一些特征,加工成可以建模使用的宽表,此时的宽表包含“全量特征”。由于银行的客户数量巨大,交易流水和APP行为更是天量数据,因此需要多名数据开发人员约2个月的时间。
宽表完成后,可以进行首次建模,得到初版模型,初版模型会尝试几种算法并选择其中最好的一种;之后针对选好的特定算法,调优模型参数,并进行特征筛选,把模型的效果调整到令人满意的程度,这个过程需要两名数据科学家约1个月的时间。模型调优完成后,还需要应用开发人员进行开发并投产上线。
但由于业务和经济环境的变化,耗时3个多月产生的模型可能使用1个月,甚至一两个星期就不准确了,然后又要花费3个月的时间重新建模,整个过程劳民伤财。
理论上传统方法的模型也可以根据反馈数据,自动迭代优化模型,但问题出在“特征筛选”这一步。由于算力问题,传统方法是从原始“全量特征”中筛选对营销效果影响大的特征来建模,然后得到最终优化的模型来投产,没有投产全量特征,所以每次模型迭代优化,只能依据筛选后的特征来重新训练模型,而由于业务和经济环境的变化,很多旧特征可能淘汰,需要新特征来支持,在这种优化模型的方式下,模型准确率依旧迅速衰减。
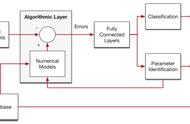
进化环机器学习法的建模流程进化环机器学习法的流程如图1所示。从“需求分析”到“建模得到初版模型”前五步与传统流程是一样的。

图1 进化环机器学习法的建模流程
从第六步开始,不进行特征筛选,而是直接使用“全量特征”,并使用效果较差的初版模型建立一个进化环。进化环包括“全量特征”“AutoML算法”“模型自动投产”以及“反馈数据”四部分,形成一个闭环。
进化环的基础是“全量特征”,由于传统方法中特征筛选导致每次建模的输入不同,所以每次重新建模都需要人工干预;而使用全量特征,则每次重新建模的输入是相同的,可以全自动执行后续流程,即自动建模算法(AutoML)和自动投产。原始的全量特征本身已经包括了各个来源的客户资产、交易、签约、APP行为数据,而为了能够增强应对各种外部变化的能力,我们在AutoML算法中加入自动特征组合等特征工程方法来提高模型准确率。投产后得到的“反馈数据”,其数据格式与“全量特征”也是一致的,所以无需人工参与。
进化环机器学习流程打通后,初始几个版本的模型不追求很高的准确性,但模型会在运行中积累新的“反馈数据”逐渐进化,提高准确性;等到准确性稳定后,模型能快速应对变化,避免迅速衰减。整个嵌入了进化环的建模流程只需要一次开发(即3个月),投产之后不用担心模型衰减的问题,解决了快速应对变化的难题,同时不需要反复人工建模,节省了大量人力资源。
进化环机器学习法在营销推荐场景中的优势以我们实现的一个理财推荐场景建模为例,建模的目标是客户的点击率,即客户打开理财页面后,会看到很多理财产品,是否会点击我们推荐给他的置顶产品。客户点击了的推荐产品为正样本,没有点击则为负样本。
在完成数据准备和清理,得到全量特征的宽表后,我们同时采用传统机器学习方法和进化环机器学习法来建模并投产。
对于两种建模方法投产后的准确率对比,传统模型在刚投产时,效果非常好,但几周后快速衰减,衰减后又开始投入人力进行建模,3个月后新模型也是同样的命运。进化环的模型在一开始可能效果不如传统模型,但随着数据积累,模型逐渐进化,准确率逐渐上升,再之后同样依靠进化环的快速迭代,始终能够保持较高的准确率。传统方法的模型更新周期需要3个月,而使用进化环的模型更新周期非常短,可以一两周甚至短到天的级别,视反馈数据的积累速度来调整,只要反馈数据足够(一般几万条产品申购记录),就可以触发进化环。
实现进化环机器学习的技术基础1.大数据的算力。由于要使用全量特征且客户数据量巨大,因此普通单节点服务器的算力是无法实现的。进化环机器学习法采用的是大数据分布式集群的算力,数据加工和处理都采用Spark技术,包括SparkSQL以及PySpark,而机器学习的核心算法运行采用基于C 的异步参数服务器方式,比普通Spark快10倍,比普通MapReduce快100倍以上。
2.适应高维特征的算法。传统机器学习算法建模流程中需要筛选特征变量,一方面是算力问题。另一方面是过拟合的问题。如果特征过多,会导致过拟合以及多重共线性问题,使模型效果大打折扣。
进化环机器学习法使用全量特征,而且对特征高维衍生,特征数会达到十万百万甚至亿的级别,所以需要能够抵御过拟合和多重共线性的算法。因此我们在普通的算法中加入L0、L1、L2正则化,可以有效解决过拟合和多重共线性问题。
3.AutoML算法。自动建模算法(AutoML)包括如下。
(1)自动特征高阶组合:将离散型特征one-hot编码之后,会自动穷举两两特征组合(甚至三阶四阶五阶特征组合),并采用因子分解机(FM)的算法来加速评估组合后对目标的提升效果,可以极大提高原始全量特征的覆盖面和完备性,提高模型准确率。
(2)自动时序流水特征提取:针对交易流水型的数据,采用时间窗口的方式,对每个客户在窗口中的各种交易行为进行统计,窗口长度会从近10笔交易遍历到近1000笔交易。
(3)自动算法选择和自动算法调参:可以尝试不同的算法和不同的参数进行比较,选择最优的算法和参数。
4.自动投产和云部署。自动投产的关键是数据和特征加工逻辑的一致性,我们在整个数据处理和建模过程中使用Dag图的形式保存完整的加工处理逻辑,因此投产时只需要将Dag图复制到生产环境,即可完成一键自动部署。
具体部署的方式采用云上微服务的方式,即将Dag图涉及的脚本、调度流程以及模型打包成Docker镜像,根据镜像在云计算K8s集群上生成容器,对外提供服务。
总结和展望本文介绍了进化环机器学习法的思想、流程以及技术特点,及其在营销推荐场景中的应用,并将其与传统的建模方法进行比较,解决了传统方法不能快速应对变化的难题,而且不需要反复人工建模,从而节省大量人力资源,在变化纷繁的客户营销场景中展现了优势。
对进化环机器学习进一步的改善,可以使用实时流计算技术(Kafka和Flink)来“加速”进化频率。例如原先的进化周期是2周1周或几天,采用了实时流计算技术后,进化周期可以缩短到小时级别。正如本文开头所述,客户上午点击过手机银行APP,当下午再打开时,推荐页面的产品已经更新。客户在手机银行APP的埋点行为数据也是准实时数据,所以准实时的进化环模型将更加精准且高效。
但加速级别取决于数据积累的速度,比如客户每天购买基金理财的交易有十几万笔,则可以加速到小时级别,而每天客户购买保险的交易很少,就不适合加速了。
另外,进化环机器学习法不仅可以用在银行的营销场景,也可以应用于风险防控、反洗钱、反欺诈等场景,让大数据和人工智能等金融科技技术全方位渗透到银行的各项业务中。
,