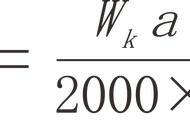图33 多层神经网络(更深的层次)
上图的网络中,虽然参数数量仍然是33,但却有4个中间层,是原来层数的接近两倍。这意味着一样的参数数量,可以用更深的层次去表达。
3.效果
与两层层神经网络不同。多层神经网络中的层数增加了很多。
增加更多的层次有什么好处?更深入的表示特征,以及更强的函数模拟能力。
更深入的表示特征可以这样理解,随着网络的层数增加,每一层对于前一层次的抽象表示更深入。在神经网络中,每一层神经元学习到的是前一层神经元值的更抽象的表示。例如第一个隐藏层学习到的是“边缘”的特征,第二个隐藏层学习到的是由“边缘”组成的“形状”的特征,第三个隐藏层学习到的是由“形状”组成的“图案”的特征,最后的隐藏层学习到的是由“图案”组成的“目标”的特征。通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。
关于逐层特征学习的例子,可以参考下图。

图34 多层神经网络(特征学习)
更强的函数模拟能力是由于随着层数的增加,整个网络的参数就越多。而神经网络其实本质就是模拟特征与目标之间的真实关系函数的方法,更多的参数意味着其模拟的函数可以更加的复杂,可以有更多的容量(capcity)去拟合真正的关系。
通过研究发现,在参数数量一样的情况下,更深的网络往往具有比浅层的网络更好的识别效率。这点也在ImageNet的多次大赛中得到了证实。从2012年起,每年获得ImageNet冠军的深度神经网络的层数逐年增加,2015年最好的方法GoogleNet是一个多达22层的神经网络。
在最新一届的ImageNet大赛上,目前拿到最好成绩的MSRA团队的方法使用的更是一个深达152层的网络!关于这个方法更多的信息有兴趣的可以查阅ImageNet网站。
4.训练
在单层神经网络时,我们使用的激活函数是sgn函数。到了两层神经网络时,我们使用的最多的是sigmoid函数。而到了多层神经网络时,通过一系列的研究发现,ReLU函数在训练多层神经网络时,更容易收敛,并且预测性能更好。因此,目前在深度学习中,最流行的非线性函数是ReLU函数。ReLU函数不是传统的非线性函数,而是分段线性函数。其表达式非常简单,就是y=max(x,0)。简而言之,在x大于0,输出就是输入,而在x小于0时,输出就保持为0。这种函数的设计启发来自于生物神经元对于激励的线性响应,以及当低于某个阈值后就不再响应的模拟。
在多层神经网络中,训练的主题仍然是优化和泛化。当使用足够强的计算芯片(例如GPU图形加速卡)时,梯度下降算法以及反向传播算法在多层神经网络中的训练中仍然工作的很好。目前学术界主要的研究既在于开发新的算法,也在于对这两个算法进行不断的优化,例如,增加了一种带动量因子(momentum)的梯度下降算法。
在深度学习中,泛化技术变的比以往更加的重要。这主要是因为神经网络的层数增加了,参数也增加了,表示能力大幅度增强,很容易出现过拟合现象。因此正则化技术就显得十分重要。目前,Dropout技术,以及数据扩容(Data-Augmentation)技术是目前使用的最多的正则化技术。
5.影响
目前,深度神经网络在人工智能界占据统治地位。但凡有关人工智能的产业报道,必然离不开深度学习。神经网络界当下的四位引领者除了前文所说的Ng,Hinton以外,还有CNN的发明人Yann Lecun,以及《Deep Learning》的作者Bengio。
前段时间一直对人工智能持谨慎态度的马斯克,搞了一个OpenAI项目,邀请Bengio作为高级顾问。马斯克认为,人工智能技术不应该掌握在大公司如Google,Facebook的手里,更应该作为一种开放技术,让所有人都可以参与研究。马斯克的这种精神值得让人敬佩。

图35 Yann LeCun(左)和 Yoshua Bengio(右)
多层神经网络的研究仍在进行中。现在最为火热的研究技术包括RNN,LSTM等,研究方向则是图像理解方面。图像理解技术是给计算
机一幅图片,让它用语言来表达这幅图片的意思。ImageNet竞赛也在不断召开,有更多的方法涌现出来,刷新以往的正确率。
六、历史回顾
影响
我们回顾一下神经网络发展的历程。神经网络的发展历史曲折荡漾,既有被人捧上天的时刻,也有摔落在街头无人问津的时段,中间经历了数次大起大落。
从单层神经网络(感知器)开始,到包含一个隐藏层的两层神经网络,再到多层的深度神经网络,一共有三次兴起过程。详见下图。

图36 三起三落的神经网络
上图中的顶点与谷底可以看作神经网络发展的高峰与低谷。图中的横轴是时间,以年为单位。纵轴是一个神经网络影响力的示意表示。如果把1949年Hebb模型提出到1958年的感知机诞生这个10年视为落下(没有兴起)的话,那么神经网络算是经历了“三起三落”这样一个过程,跟“小平”同志类似。俗话说,天将降大任于斯人也,必先苦其心志,劳其筋骨。经历过如此多波折的神经网络能够在现阶段取得成功也可以被看做是磨砺的积累吧。
历史最大的好处是可以给现在做参考。科学的研究呈现螺旋形上升的过程,不可能一帆风顺。同时,这也给现在过分热衷深度学习与人工智能的人敲响警钟,因为这不是第一次人们因为神经网络而疯狂了。1958年到1969年,以及1985年到1995,这两个十年间人们对于神经网络以及人工智能的期待并不现在低,可结果如何大家也能看的很清楚。
因此,冷静才是对待目前深度学习热潮的最好办法。如果因为深度学习火热,或者可以有“钱景”就一窝蜂的涌入,那么最终的受害人只能是自己。神经网络界已经两次有被人们捧上天了的境况,相信也对于捧得越高,摔得越惨这句话深有体会。因此,神经网络界的学者也必须给这股热潮浇上一盆水,不要让媒体以及投资家们过分的高看这门技术。很有可能,三十年河东,三十年河西,在几年后,神经网络就再次陷入谷底。根据上图的历史曲线图,这是很有可能的。
2.效果
下面说一下神经网络为什么能这么火热?简而言之,就是其学习效果的强大。随着神经网络的发展,其表示性能越来越强。
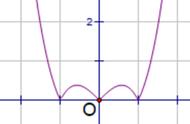
从单层神经网络,到两层神经网络,再到多层神经网络,下图说明了,随着网络层数的增加,以及激活函数的调整,神经网络所能拟合的决策分界平面的能力。
图37 表示能力不断增强
可以看出,随着层数增加,其非线性分界拟合能力不断增强。图中的分界线并不代表真实训练出的效果,更多的是示意效果
神经网络的研究与应用之所以能够不断地火热发展下去,与其强大的函数拟合能力是分不开关系的。
3.因素
当然,光有强大的内在能力,并不一定能成功。一个成功的技术与方法,不仅需要内因的作用,还需要时势与环境的配合。神经网络的发展背后的外在原因可以被总结为:更强的计算性能,更多的数据,以及更好的训练方法。只有满足这些条件时,神经网络的函数拟合能力才能得已体现,见下图。