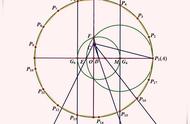
中间是一个二元正态分布。图左是该分布关于 Y 做边缘化的结果,类似于沿着 Y 轴做累加。图右是以给定的 X 为条件的分布,类似于在原始分布上切下一刀。你可以通过拖动图中的点来修改这个高斯分布和作为条件的变量。
高斯过程复习好了多元高斯分布的基础属性,我们接着就可以把它们组装到一起,来定义高斯过程,并展示怎么用高斯过程来解决回归问题。
首先,我们把视角从连续函数转移到函数的离散表达:相比于找一个隐函数而言,我们对预测具体点的函数值更感兴趣,这些点叫做测试点 X。对应地,我们把训练数据称为 Y。那么,高斯过程背后的关键点在于所有的函数值都来源于多元高斯分布。这意味着联合概率分布 P(X,Y) 跨越了我们想要预测的函数的可能取值空间。这个测试数据和训练数据的联合分布有∣X∣ ∣Y∣维。
为了在训练数据上进行回归,我们会用贝叶斯推断来处理这个问题。贝叶斯推断的核心思想就是:在获得新的信息以后,更新当前的假设。对于高斯过程来说,这个信息指的就是训练数据。因此,我们感兴趣的是条件概率 P(X|Y)。最后,还记得高斯分布在条件作用下是封闭的吗?所以 P(X|Y) 也是正态分布的。
好了,我们已经集齐了高斯过程的基本框架,只差一个东西:我们怎么才能建立起这个分布,定义均值μ 和协方差矩阵Σ?方法是:使用核函数 k,具体细节将在下一节具体讨论。但在这之前,我们先回忆一下怎么用多元高斯分布来估算函数值。下图中的例子包含十个测试点,我们将在十个点上预测函数。

这也是一个互动式的图
在高斯过程中,我们把每个测试点作为一个随机变量,多元高斯分布的维数和随机变量的数目一致。由于我们想要预测函数在∣X∣=N 个测试点上的取值,对应的多元高斯分布也是 N 维的。用高斯过程做预测最终可以归结为在这个分布上做采样。这样,我们就可以把结果向量上的第 i 个成员作为第 i 个测试点的对应函数值。
核函数
让我们回想一下,为了建立起我们要的分布,首先要定义 μ 和 Σ。在高斯过程中,我们往往假设 μ =0,这样可以简化条件作用所需要的公式。这样做假设总是没错的,就算 μ≠0,我们也可以在预测结束后把μ 加回到结果函数值中。所以配置μ 非常简单,更有意思的是这个分布的另一个参数。
高斯过程中巧妙的一步是如何设置协方差矩阵Σ。协方差矩阵不仅仅描述了这个分布的形状,也最终决定了我们想要预测的函数所具有的特性。我们通过求核函数 k 的值来生成协方差矩阵,这个核函数通常也被称为协方差函数,作用在两两成对的所有测试点上。核函数接收到的输入是两个点,

,返回的是一个标量,表达了这两个点之间的相似度。

我们将测试点两两配对,在这个函数上求值以获取协方差矩阵,这个步骤在下图中也有所显示。为了对核函数的作用有一个更直观的理解,我们可以想一想协方差矩阵中元素描述的是什么。Σ_ij 描述的是第 i 个点和第 j 个点之间的相互影响,这和多元高斯分布的定义一致。在多元高斯分布的定义中,Σ_ij 定义了第 i 个随机变量和第 j 个随机变量之间的相关性。由于核函数描述的是函数值之间的相似度,它便控制了这个拟合函数可能拥有的形状。注意,当我们选择一个核函数时,我们要确保它生成的矩阵遵循协方差矩阵的属性。
核函数被广泛应用于机器学习,比方说支持向量机。它之所以这么受欢迎,是因为它让我们得以在标准的欧几里得距离(L2 距离)之外衡量相似度。很多核函数会把输入点嵌到更高维的空间里去测量相似度。下图介绍了高斯过程的一些常见核函数。对于每个核函数,我们用 N=25 个呈线性、范围在 [-5,5] 的点生成协方差矩阵。矩阵中的元素显示出点和点之间的协方差,取值在 [0,1] 之间。