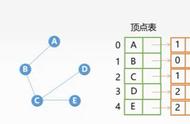
在文章[6]中,作者还引入了多头注意力,结构如图5所示,公式如(13)所示:

图5 多头注意力机制结构

多头注意力本质是引入并行的几个独立的注意力机制,可以提取信息中的多重含义,防止过拟合。
2.3 GraphSAGE -归纳式学习框架
提到GraphSAGE[7]模型, 不得不又提到GCN,我们回顾一下GCN的迭代公式:

图中红框位置所做的操作可以简单理解为对邻接矩阵A的归一化变换,去掉该部分会发现剩下的结构等同于深度神经网络,加上红色部分后,通过矩阵乘法实际上所做的就是将节点与节点相邻节点特征信息进行相加。
GraphSAGE在特征聚合方式上与GCN简单相加不同,GraphSAGE支持max-pooling、LSTM、mean等聚合方式。另外,GraphSAGE与GCN的最大不同点在于,GCN是直推式方法,即所有节点都在图中,对于新出现的节点无法处理。GraphSAGE是归纳式,对于没见过的节点也能生成embedding。
GraphSAGE的传播方法如图6所示: