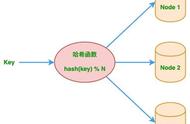
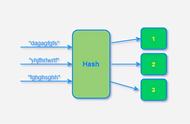
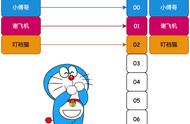
如上图所示,这里其实是分了10张表,openid计算后的hash值取模10,得到对应的分表,在进行后续处理就好。对于一般的活动或者系统,我们一般设置10张表或者100张表就好。
下面我们来看一点复杂的问题,假设我们活动初始分表了10张,运营一段时间以后发现需要10张不够,需要改到100张。这个时候我们如果直接扩容的话,那么所有的数据都需要重新计算Hash值,大量的数据都需要进行迁移。如果更新的是缓存的逻辑,则会导致大量缓存失效,发生雪崩效应,导致数据库异常。造成这种问题的原因是hash算法本身的缘故,只要是取模算法进行处理,则无法避免这种情况。针对这种问题,我们就需要利用一致性hash进行相应的处理了。
一致性hash的基本原理是将输入的值hash后,对结果的hash值进行2^32取模,这里和普通的hash取模算法不一样的点是在一致性hash算法里将取模的结果映射到一个环上。将缓存服务器与被缓存对象都映射到hash环上以后,从被缓存对象的位置出发,沿顺时针方向遇到的第一个服务器,就是当前对象将要缓存于的服务器,由于被缓存对象与服务器hash后的值是固定的,所以,在服务器不变的情况下,一个openid必定会被缓存到固定的服务器上,那么,当下次想要访问这个用户的数据时,只要再次使用相同的算法进行计算,即可算出这个用户的数据被缓存在哪个服务器上,直接去对应的服务器查找对应的数据即可。这里的逻辑其实和直接取模的是一样的。如下图所示:

初始情况如下:用户1的数据在服务器A里,用户2、3的数据存在服务器C里,用户4的数据存储在服务器B里
下面我们来看一下当服务器数量发生变化的时候,相应影响的数据情况:
服务器缩容

服务器B发生了故障,进行剔除后,只有用户4的数据发生了异常。这个时候我们需要继续按照顺时针的方案,把缓存的数据放在用户A上面。
服务器扩容
同样的,我们进行了服务器扩容以后,新增了一台服务器D,位置落在用户2和3之间。按照顺时针原则,用户2依然访问的是服务器C的数据,而用户3顺时针查询后,发现最近的服务器是D,后续数据就会存储到d上面。

虚拟节点
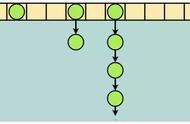
当然这只是一种理想情况,实际使用中,由于服务器节点数量有限,有可能出现分布不均匀的情况。这个时候会出现大量数据都被映射到某一台服务器的情况,如下图左侧所示。为了解决这个问题,我们采用了
虚拟节点的方案。虚拟节点是实际节点(实际的物理服务器)在hash环上的复制品,一个实际节点可以对应多个虚拟节点。虚拟节点越多,hash环上的节点就越多,数据被均匀分布的概率就越大。